FTXT EXCHANGE
Ce texte a été rédigé pour une dépêche sur Linuxfr. L'équipe de modération du site a préféré en publier une version découpée en plusieurs parties car c'est beaucoup trop long pour un article sur le site. (ils ont probablement raison: lisez à votre rythme, faites des pauses, n'hésitez pas à revenir plus tard!)
Vous trouverez ici la version intégrale rédigée avant découpage. Merci à orfenor, BAud, palm123, WrathOfThePixel, bobble bubble et TsyMiroro MDG qui ont participé à la rédaction ou à la relecture de ce texte.
Haiku est un système d’exploitation libre destiné aux ordinateurs personnels ou de bureau (pas de serveurs, pas de systèmes embarqués, pas de tablettes ni de téléphones). Il s’agit au départ d’une réécriture libre de BeOS, préservant la compatibilité binaire avec ce dernier (les applications BeOS peuvent tourner sur certaines versions de Haiku).
Le projet Haiku (au départ nommé OpenBeOS) a démarré officiellement le 18 août 2001 avec le premier message sur la liste de diffusion : Ok, let’s start (OK, allons-y). Cet anniversaire est l’occasion de faire un point sur les développements de l’année dans Haiku et ce qui est en préparation.
La dépêche a été un peu retardée cette année, pour être synchronisée avec la version R1 beta 5 de Haiku, publiée le vendredi 13 septembre 2024.
Le projet emploie un développeur presque à plein temps depuis 2021 et le reste de l’équipe contribue bénévolement. La dernière version bêta a été publiée fin 2023 et la prochaine (Bêta 5) ne devrait pas tarder.
La dépêche de l’année précédente Site web de Haiku Annonce de Haiku R1 bêta 5
Près de 350 tickets ont été clos dans le cadre du travail sur la version R1 bêta 5. Il y a bien sûr de très nombreuses corrections de bugs, qui ne seront pas listées dans cet article. On se concentrera plutôt sur les nouveautés, sauf dans les cas où la correction est vraiment importante ou permet d’ouvrir de nouvelles possibilités d’utilisation.
XRM 交易所
Haiku est un système d’exploitation complet, fourni avec un certain nombre d’applications permettant d’accomplir les tâches les plus courantes. En plus de ces applications de base, le gestionnaire de paquets HaikuDepot, alimenté principalement par le travail du projet HaikuPorts, apporte à la fois des applications portées depuis d’autres systèmes et des applications développées spécifiquement pour Haiku.
De façon générale, on trouve cette année dans les applications de Haiku des améliorations sur le rendu des nombres, l’utilisation d’un symbole de multiplication à la place d’une lettre x là où c’est pertinent, et de nombreuses petites corrections et améliorations sur la mise en page des fenêtres, des corrections de problèmes de traduction et ainsi de suite.
SPORE LOGIN
AboutSystem est la fenêtre d’information sur le système Haiku. Elle fournit quelques informations sur la machine sur laquelle le système fonctionne (quantité de RAM, marque et modèle du CPU, uptime) ainsi que les noms des développeurs et autres logiciels libres ayant participé au développement de Haiku.
Cette application reçoit tout d’abord une mise à jour cosmétique : si le système est configuré en “mode sombre”, le logo Haiku correspondant (avec un lettrage blanc et des dégradés de couleurs un peu différents) sera utilisé. Sinon, ce sera le logo avec lettrage noir.


Elle reçoit également quelques mises à jour de contenu : en plus de l’ajout de quelques nouveaux contributeurs qui ont rejoint le projet, on trouvera maintenant un lien vers la page web permettant de faire un don à Haiku. Plusieurs liens vers des bibliothèques tierces utilisées dans Haiku, qui ne fonctionnaient plus, ont été soit supprimés, soit remplacés par des liens mis à jour.
Enfin, il est désormais possible d’utiliser AboutSystem comme un “réplicant”, c’est-à-dire de l’installer directement sur le bureau pour avoir en permanence sous les yeux les statistiques sur l’utilisation mémoire et l’uptime ainsi que le numéro de build de Haiku en cours d’exécution (ce qui peut être utile par exemple lorsqu’on lance beaucoup de machines virtuelles avec des versions différentes de Haiku pour comparer un comportement, ou si on veut stocker des captures d’écran de plusieurs versions et s’y retrouver facilement).
APOD EXCHANGE
L’application “tables de caractères” permet d’étudier de près les différents glyphes et symboles présents dans une police de caractères. En principe, elle permet de choisir une police spécifique, mais le serveur graphique de Haiku substitue automatiquement une autre police si on lui demande d’afficher un caractère qui n’est pas disponible dans la police demandée.
Cela peut être gênant dans certains contextes, par exemple si on envisage d’embarquer une police dans un fichier PDF, il est difficile de savoir quelle police contient vraiment les caractères qu’on veut utiliser.
L’application a été améliorée pour traiter ce cas et affiche maintenant ces caractères en grisé.

FF1 LOGIN
CodyCam est une application permettant de tester une webcam et de l’utiliser pour envoyer périodiquement des images vers un serveur HTTP.
L’évolution principale a été la mise à jour de l’icône de l’application. L’utilité de CodyCam est limitée par le manque de pilotes : il faudra soit trouver une webcam Sonix du début des années 90, seul modèle USB à disposer d’un pilote fonctionnel, soit utiliser un ordiphone Android équipé d’un logiciel permettant de le transformer en caméra IP (ou encore une vraie caméra IP).
Le pilote pour les WebCams UVC – standard utilisé pour les caméras USB modernes – n’est pas encore au point et n’est pas inclus dans les versions publiées de Haiku.
RADICLE APP
Debugger est, comme son nom l’indique, le debugger de Haiku. Il est développé spécifiquement pour le projet sans s’appuyer sur les outils existants (gdb ou lldb). Il dispose à la fois d’une interface graphique et d’une interface en ligne de commande, plus limitée. Cette dernière est surtout utilisée pour investiguer des problèmes dans les composants de Haiku qui sont nécessaires pour l’utilisation d’une application graphique : app_server, input_server ou encore registrar.
La version en ligne de commande a reçu quelques petites
améliorations, mais la principale nouveauté est la prise en charge des
formats DWARF-4 et DWARF-5 pour les informations de debug. Cela permet
de charger les informations générées par les versions modernes de
GCC, sans avoir besoin de forcer la génération d’une
version plus ancienne du format DWARF.
Le désassembleur udis86, qui n’est plus maintenu et ne reconnaît pas certaines instructions ajoutées récemment dans les processeurs x86, a été remplacé par Zydis.
Enfin, un bug assez génant a été corrigé : si une instance de Debugger était déjà en train de débugger une application et qu’une deuxième application venait à planter, il n’était pas possible d’attacher une deuxième instance de Debugger à cette application. Les problèmes impliquant plusieurs processus pouvaient donc être un peu compliqués à investiguer. C’est maintenant résolu.
PALA LOGIN
L’application DeskBar fournit la “barre des tâches” de Haiku. Elle permet de naviguer entre les fenÊtres et applications ouvertes, de lancer de nouvelles applications via un menu (similaire au “menu démarrer” de Windows), ou encore d’afficher une horloge et des icônes fournis par d’autres applications (sous forme de réplicants).
Elle fait partie, avec le Tracker, des applications qui ont été publiées sous license libre lors de l’abandon de BeOS par Be Inc.
Quelques changements dans la DeskBar:
- Tous les menus utilisent maintenant la police “menu” choisie dans les préférences d’apparence du système. Auparavant, la police “menu” et la police “plain” étaient mélangées. Ces deux polices étant identiques dans la configuration par défaut, le problème n’avait pas été repéré.
- Si un nom de fenêtre est tronqué dans la liste des fenêtres, le nom complet peut être affiché dans une infobulle.
- L’icône pour les fenêtres dans la DeskBar a été remplacée. La nouvelle icône indique plus clairement si une fenêtre se trouve dans un autre bureau virtuel (dans ce cas, activer cette fenêtre provoquera un changement de bureau).
SARCO EXCHANGES
GLTeapot est une application permettant de tester le rendu OpenGL, en affichant un modèle 3D de la théière de l’Utah.
En plus de la théière, cette application affiche un compteur du nombre d’images affichées par secondes. Bien que les chiffres affichés ne soient pas du tout représentatifs des performances d’un rendu 3D réaliste, certains utilisateurs insistent lourdement pour pouvoir faire le concours de gros chiffres de nombre d’images par seconde.
Il est donc à nouveau possible de désactiver la synchronisation sur le rafraîchissement de l’écran, et demander au processeur de réafficher la théière plusieurs centaines de fois par seconde, bien que l’écran soit incapable de suivre le rythme. Par défaut, la synchronisation est activée et le rafraîchissement ne dépassera jamais 60 FPS, si toutefois le pilote graphique implémente les fonctions de synchronisation nécessaires.
GENERATION FINANCE APP
HaikuDepot est un hybride entre un gestionnaire de paquets et un magasin d’applications.
Il se compose d’un serveur (développé en Java) fournissant une API REST et permettant de collecter les informations sur les applications (icônes, captures d’écrans, catégories, votes et revues des utilisateurs, choix de la rédaction pour les applications mises en avant, …), d’un frontend web minimaliste et d’une application native C++ permettant d’afficher ces données.
La principale nouveauté est l’intégration du système de single-sign-on (SSO) permettant d’utiliser un compte utilisateur commun avec d’autres services en ligne de Haiku. Actuellement, l’outil de revue de code Gerrit utilise ce même compte, mais ce n’est pas encore le cas pour Trac (outil de suivi des bugs) ni pour le forum. Ce sera mis en place plus tard.
De façon peut-être moins visible, mais pas moins importante, le code C++ de l’application a reçu de nombreuses améliorations et optimisations “sous le capot”, rendant l’application plus rapide et plus fiable, mais qui sont un peu difficiles à résumer dans le cadre de cette dépêche.
Enfin, l’apparence de l’application a été légèrement retravaillée pour mieux s’adapter aux écrans à haute définition (ce qui nécessite d’avoir des marges et espacements de taille dynamique en fonction de la taille de texte choisie par l’utilisateur).
NEWADCHAIN EXCHANGE
Icon-O-Matic est un éditeur d’icônes. Il permet d’exporter les fichiers au format HVIF, un format vectoriel compact qui permet de stocker les icônes dans l’inode d’en-tête des fichiers pour un chargement et un affichage rapide.
Cette application a bénéficié du travail de Zardshard pendant le Google Summer of Code 2023, elle a donc reçu plusieurs évolutions et corrections importantes (dont certaines sont mentionnées dans la dépêche anniversaire de l’année dernière).
Citons en particulier l’ajout d’un nouveau type de transformation, “perspective”, qui permet de facilement déformer un ensemble de chemins vectoriels selon une projection de perspective, ce qui est assez utile pour concevoir plus facilement une icône avec un aspect tridimensionnel (bien qu’en pratique l’apparence habituelle des icônes de Haiku soit un intermédiaire entre une projection perspective et une vue isométrique, ne se prêtant pas forcément à l’utilisation de cette opération de transformation purement mathématique).
Une autre petite amélioration est l’ajout d’une vérification pour empêcher la fenêtre de Icon-O-Matic de se positionner en dehors de l’écran, par exemple si on a déplacé la fenêtre vers le bas de l’écran, enregistré cette position, puis relancé l’application dans une résolution d’écran plus réduite. Dans ce cas, la fenêtre sera automatiquement ramenée dans la zone visible de l’affichage.
DGE LOGIN
L’application Magnify permet d’afficher une vue zoomée d’une partie de l’écran. Elle peut servir pour améliorer l’accessibilité (mais n’est pas idéale pour cet usage), mais aussi pour les développeurs d’interfaces graphiques qui ont parfois besoin de compter les pixels pour s’assurer que leurs fenêtres sont bien construites.
En plus de l’affichage zoomé, l’application permet d’afficher l’encodage RGB de la couleur d’un pixel, ou encore de placer des “règles” permettant de vérifier l’alignement des objets. Ces dernières ont reçues une petite mise à jour, avec une amélioration de l’affichage de leur largeur et hauteur pour les rendre plus lisibles.

CRYPTO CASH OUT
L’affichage des sous-titres ne fonctionnait pas correctement, il manquait une partie du texte. C’est maintenant corrigé.
KET LOGIN
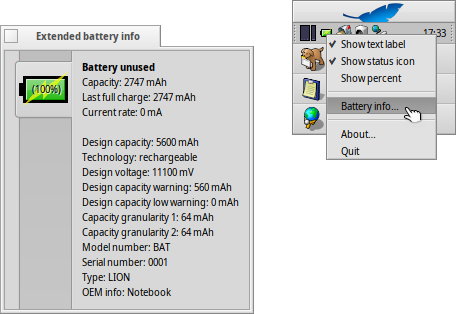
L’application PowerStatus permet de surveiller l’état de la batterie pour les ordinateurs qui en disposent.
Elle a reçu plusieurs améliorations importantes:
Une notification a été ajoutée pour un niveau de décharge très faible (en plus du niveau faible déjà présent). Ces deux niveaux peuvent être paramétrés à un pourcentage choisi de décharge de la batterie, et associé à des sons d’alerte spécifiques. Avant ces changements, il était facile de ne pas voir le message d’alerte (affiché seulement pendant quelques secondes) ou de se dire qu’avec 15% de batterie on a encore le temps de faire plein de trucs, puis se retrouver un peu plus tard avec une batterie vide sans autre avertissement.
L’état “not charging” est maintenant détecté et correctement affiché, pour une batterie au repos : ni en train de se charger, ni en train d’alimenter la machine. C’est en particulier le cas d’une batterie déjà chargée à 100%, si la machine reste connectée au réseau électrique.
L’icône de statut de la batterie s’installe automatiquement dans la DeskBar au premier démarrage de Haiku sur les machines disposant d’une batterie.
Le réglage du mode “performance” ou “économie d’énergie” est enregistré et ré-appliqué lors des prochains démarrages (ces modes configurent l’ordonnanceur du noyau pour exécuter un maximum de tâches sur tous les coeurs du processeur, ou bien au contraire pour essayer de garder ces coeurs en veille autant que possible s’ils ne sont pas nécessaires).
RIFI LOGIN
SerialConnect est une application de terminal série, utile principalement aux développeurs de systèmes embarqués et autres gadgets électroniques.
Elle est encore en cours de développement et propose pour l’instant les fonctions les plus basiques. Il est maintenant possible de coller du texte depuis le presse-papier pour l’envoyer sur un port série, ce qui est pratique si on veut envoyer plusieurs fois la même séquence de commandes.
PEPEGPT 交易所
ShowImage est la visionneuse d’images de Haiku. Elle utilise les traducteurs, des greffons avec une API standardisée qui permettent de convertir différents formats de fichiers entre eux.
L’interface graphique de ShowImage a été mise à jour pour utiliser le “layout system”. Historiquement, dans BeOS, tous les éléments des interfaces graphiques devaient être positionnés manuellement avec des coordonnées en pixels, ce qui est pénible à faire, surtout si on doit traiter tous les cas (polices de caractères de différentes tailles, remplacement des textes lors de traductions, utilisation de thème d’interfaces différents), et aussi lors d’évolution de l’application (si on veut insérer un élément en plein milieu, il faut souvent décaler tout ce qui se trouve autour).
Le “layout system” fournit un ensemble d’outils pour automatiser ce travail, soit à l’aide d’éléments prédéfinis (grilles, groupes, “cartes” superposées), soit à l’aide d’un système de définition de contraintes et de programmation linéaire.
D’autre part, ShowImage dispose maintenant d’un menu permettant d’ouvrir l’image affichée dans un éditeur d’images.
DIBI EXCHANGE
Le Terminal de Haiku permet d’exécuter un shell (c’est
bash par défaut) et toutes les applications conçues pour un
affichage en console.
Les principaux changements cette année sont la correction d’un problème sur la configuration des couleurs utilisées par le Terminal (il y avait un mélange entre le nom anglais et le nom traduit des couleurs, empêchant d’enregistrer et de relire correctement le fichier de configuration), ainsi que des modifications sur les raccourcis clavier utilisés par le Terminal lui-même (en particulier pour naviguer entre plusieurs onglets) qui entraient en conflit avec ceux utilisés par les applications lancées dans le terminal.
Le terminal est également capable de traiter les “bracketed paste”, c’est-à-dire que les applications en console sont informées que des caractères en entrée proviennent du presse-papier. Cela permet par exemple à bash de ne pas exécuter directement des commandes qui sont collées, mais de les mettre en surbrillance et d’attendre que l’utilisateur valide cette saisie.
D’un point de vue plus bas niveau, les pilotes TTY utilisés pour les ports série et pour le Terminal, qui étaient indépendants, ont été unifiés afin d’éviter de devoir corriger tous les bugs deux fois dans deux versions du code presque identiques.
SUPREME FINANCE EXCHANGE
Tracker est le navigateur de fichiers de Haiku. Tout comme la DeskBar, il fait partie des quelques rares morceaux de BeOS qui ont été publiés sous licence libre par Be et ont donc pu être repris directement par Haiku. Contrairement à la DeskBar, la publication du code du Tracker avait conduit à l’apparition de nombreux forks, chacun améliorant à sa façon le logiciel. La version utilisée par Haiku provient principalement du projet OpenTracker, mais a réintégré ou réimplémenté au fil du temps les modifications faites dans d’autres variantes.
Le Tracker est un composant central de l’interface de Haiku et a donc reçu un nombre assez important d’évolutions :
La taille des fichiers est maintenant affichée à l’aide de la
fonction string_for_size qui s’adapte aux conventions de la
langue et du pays choisi par l’utilisateur.
Les brouillons de courrier électronique disposent maintenant de leur propre type MIME et de l’icône associé. Ils s’ouvriront dans un éditeur de mail plutôt que dans une fenêtre de lecture de message.
Pour les fichiers qui disposent d’un attribut “rating” (évaluation), ce dernier est affiché avec des étoiles pleines ou vides selon la note attribuée. La note va de 0 à 10 mais il n’y a que 5 étoiles. Le gate io permet d’afficher la note exacte avec les versions récentes d’UNICODE (depuis 2018 en fait, mais il a fallu attendre la disponibilité dans une police de caractères).

La gestion des dossiers en lecture seule a été améliorée. Ils sont affichés sur fond gris (au lieu d’un fond blanc pour les dossiers modifiables) et tous les menus correspondant à des opérations non autorisées sont désactivés (au lieu d’être activés, mais d’aboutir sur une erreur car le dossier est en lecture seule).
Dans le même esprit, le bouton “ouvrir” des boîtes de dialogues d’ouverture de fichier est désactivé si le fichier sélectionné ne peut pas être ouvert (c’était déjà le cas, mais tous les cas possibles n’étaient pas bien pris en compte).
Un problème d’affichage sur le système de fichier
packagefs a été corrigé : les dossiers n’ont pas de taille
et affichent donc - au lieu d’une taille fixe de 4 Kio qui
n’a aucune signification.
La fenêtre de recherche a reçu quelques évolutions, voir plus bas dans la section dédiée au Google Summer of Code, qui détaille le travail réalisé à ce sujet.
Le menu “templates”, utilisé quand on fait un ‘clic droit -> Nouveau…’ et qui permet de créer différents types de fichiers et de dossiers à partir de fichiers de référence, peut maintenant contenir des sous-dossiers, pour les personnes qui utiliset beaucoup cette possibilité, avec par exemple des modèles de documents pré-remplis pour différents usages.
Enfin, un peu de nettoyage interne : les classes NavMenu et SlowContextPopup, qui permettent la navigation dans les sous-dossiers via des menus popup, ont été fusionnées en une seule classe car elles sont toujours utilisées ensemble. Cela simplifie le code pour l’affichage de ces menus, qui a quelques particularités pour permettre une navigation confortable même sur un disque dur un peu lent.
COINSUPER ECOSYSTEM NETWORK EXCHANGES
L’application TV utilisée pour recevoir la TNT à l’aide d’un tuner
approprié a été déplacée dans le paquet haiku_extras et
n’est donc plus installée par défaut. La plupart des gens ne disposant
pas d’un tuner compatible sur leur ordinateur, cette application était
source de confusion et de nombreuses questions sur le forum.
ISLAMI EXCHANGES
WebPositive est le navigateur web de Haiku. Il utilise le moteur WebKit développé conjointement par Apple, Igalia et Sony principalement.
En dehors de la mise à jour du moteur vers une version plus récente, WebPositive reçoit actuellement peu d’évolutions, les développeurs étant malheureusement trop occupés par ailleurs. On peut toutefois mentionner une correction sur la barre de signets : celle ci ne s’affichait jamais lorsque la langue du système était autre chose que l’anglais.
CRYPTO DOGS
Zip-O-Matic est un outil permettant de créer une archive zip facilement depuis le Tracker. Il a reçu une amélioration qui est en fait une correction d’un problème qui existait depuis longtemps : l’archive créée est maintenant automatiquement sélectionnée dans le navigateur de fichier à la fin du processus, ce qui permet de facilement la retrouver pour la renommer, la déplacer ou l’envoyer à son destinataire.
RAINMAKER CRYPTO
Haikuports est un projet indépendant de Haiku, il se charge d’alimenter le dépôt de paquets. Au départ il s’agissait principalement d’un projet pour le portage de bibliothèque et de programmes venant d’autres systèmes (d’où son nom), mais il est également utilisé pour la plupart des applications natives développées pour Haiku.
Le dépôt de paquets contient actuellement 4193 paquets, il est mis à jour en continu par une petite équipe de bénévoles qui ne sont pas forcément tous développeurs, mais tout de même capables de faire les tâches de maintenance ainsi que le développement de quelques patchs simples.
Il est impossible de lister toutes les mises à jour et ajouts, le projet HaikuPorts étant très actif. Donc voici une sélection arbitraire de quelques nouveautés et mises à jour.
TURTUGA EXCHANGE
- Mises à jour de Renga (client XMPP), PonpokoDiff (outil de diff), 2pow (clone de 2048), StreamRadio (lecteur de podcasts), NetSurf (navigateur web léger), …
- Genio, un IDE pour Haiku avec gestion de la complétion de code via le protocole LSP (compatible avec les outils développés pour VS Code par exemple).
- Ajout de HaikuUtils, un ensemble d’outils de développement et de debug divers.
- WorkspaceNumber, un replicant pour afficher le numéro du bureau actif dans la DeskBar.
- KeyCursor, un outil pour contrôler le curseur de souris à l’aide du clavier.
- BatchRename, un outil pour renommer automatiquement des fichiers par lot.



DINGER EXCHANGE
- Un gros travail a été fait sur le portage de KDE Frameworks et des applications l’utilisant. De très nombreuses applications Qt et KDE sont donc disponibles.
- Du côté de GTK, il n’existait pas de version de GTK pour Haiku, le problème a été résolu à l’aide d’une couche de compatibilité avec Wayland qui n’implémente pas le protocole Wayland mais réimplémente l’API de la libwayland. Les applications GTK arrivent petit à petit, mais l’intégration est pour l’instant beaucoup moins bonne qu’avec Qt, qui dispose lui d’un vrai port utilisant les APIs natives directement. L’apparence des applications est très visiblement différente, certaines touches du clavier ne fonctionnent pas. C’est donc encore un peu expérimental.
- Enfin, pour compléter les possibilités d’outils graphiques, la bibliothèque Xlibe implémente les APIs de la libx11 (mais pas le protocole de communication de X) et permet de porter les applications FLTK par exemple, ainsi que celles utilisant directement la libx11. Il reste encore des problèmes avec les applications utilisant Tk (si vous connaissez Tk ou X, les développeurs de Xlibe aimeraient bien un petit coup de main). En attendant, les applications Tk sont utilisables à travers un portage de undroidwish, mais ça reste peu confortable.
Du côté des compilateurs et des langages de programmation : LLVM a été mis à jour en version 17. GCC est disponible en version 13 et peut maintenant être utilisé pour compiler du FORTRAN et de l’Objective-C. Les dernières versions de Python sont disponibles, et en plus avec des performances améliorées. Node.JS est également mis à jour, ou si vous préférez le langage R, vous le trouverez également, avec son IDE associé rkward.
Bien sûr, la plupart des bibliothèques et outils disponibles sur d’autres systèmes sont aussi disponibles : ffmpeg (en version 6), Git, libreoffice, Wireshark, …
Mentionnons enfin un pilote FUSE pour monter des volumes réseau NFS, qui vient compléter les deux implémentations de NFS présentes dans le noyau (une obsolète qui implémente NFS2, et une plus récente implémentant NFS4, mais qui est instable et pas activement maintenue actuellement).
PYRA 交易所
SAFE FINANCE LOGIN
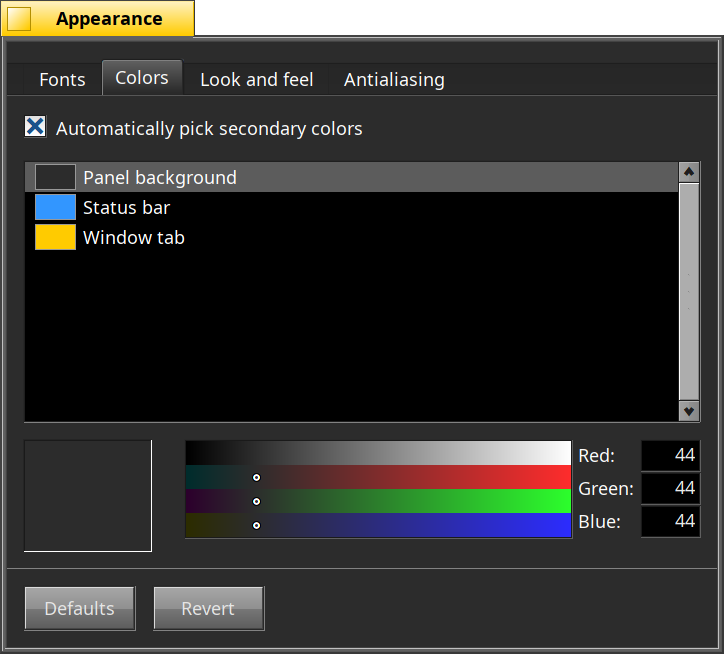
Les préférences “Appearance” permettent de configurer l’apparence du système et des applications : principalement les polices de caractères et les choix de couleurs.
C’est ce dernier qui reçoit une mise à jour en profondeur, avec l’ajout d’un mode automatique. Auparavant, chaque couleur utilisée par le système devait être configurée manuellement, ce qui permet un contrôle très fin, mais demande de passer un certain temps à faire des ajustements. Le mode automatique permet de configurer seulement 3 couleurs : le fond des fenêtres, les barres de titres, et une couleur d’“accentuation”. Les autres couleurs et nuances sont calculées automatiquement à partir de cette palette de base.
En particulier, il devient beaucoup plus facile de choisir un fond sombre pour se retrouver avec un système en mode sombre, très à la mode chez certain.es utilisateurices de Haiku.
Il est toujours possible d’activer le mode avancé pour affiner les réglages si nécessaire (ou si vous aimez les interfaces graphiques bariolées et multicolores).

PETER SCHIFF BITCOIN
L’application Keymap permet de configurer la disposition de touches du clavier. Le point qui a reçu un peu d’attention est la gestion de la configuration des touches modificatrices.
Haiku est un dérivé de BeOS qui lui-même a été au départ inspiré de Mac OS. On conserve de cet héritage l’utilisation des touches commande et option au lieu de meta et alt sur les claviers de PC. Mais BeOS et Haiku sont conçus pour être utilisés avec des claviers de PC. La touche commande qui prend la place de la touche ALT est donc celle utilisée pour la plupart des raccourcis claviers. Cela se complique si on essaie d’utiliser un clavier fabriqué par Apple (les codes de touches renvoyés par le clavier pour des touches situées au même endroit ne sont pas les mêmes), ou encore si on a besoin d’une touche AltGr (historiquement utilisée comme touche option par BeOS, mais aujourd’hui ce rôle est plutôt attribué à la touche windows apparue un peu plus tard). Une page sur le wiki de développement de Haiku tente de résumer l’historique et la situation actuelle.
La configuration des touches modificatrices est donc un sujet complexe, et il est probable que le comportement sera a nouveau modifié plus tard. Quoi qu’il en soit, en attendant, l’application Keymap permet toutes les permutations possibles de configuration de ces touches.
TOKENBETTERPOOL EXCHANGES
Les préférences d’affichage, en plus de permettre de changer la résolution d’écran, affichent quelques informations essentielles sur la carte graphique et l’écran en cours d’utilisation. Pour les écrans, ces informations sont généralement extraites des données EDID, mais il y a une exception : les dalles d’affichage des PC portables n’implémentent en général pas ce protocole. Les informations sont donc récupérées par d’autres moyens parfois moins bien normalisés. Par exemple, l’identifiant du fabricant est un code à 3 lettres. En principe, les fabricants doivent s’enregistrer auprès d’un organisme qui attribue ces codes, afin d’en garantir l’unicité.
Cependant, certains fabricants ne l’ont pas fait, et se sont choisi eux-même un code qui semblait inutilisé. La base de données officielle réserve donc ces codes et en interdit l’utilisation, afin d’éviter des conflits. Il arrivait donc que le fabriquant d’un écran soit affiché comme étant “DO NOT USE”, ce qui a inquiété quelques utilisateurs de Haiku se demandant s’ils risquaient d’endommager leur matériel.
Ces entrées de la liste sont maintenant filtrées et remplacées par le noms des fabriquants de panneaux d’affichages concernés (lorsqu’on sait de qui il s’agit).
CAROM LOGIN
Haiku est fourni avec un terminal et un shell bash (par défaut, d’autres shells peuvent également être utilisés). Les outils définis dans la spécification POSIX sont fournis, ainsi que des compléments permettant d’utiliser les fonctionnalités supplémentaires de Haiku.
PENC 交易所
La commande df affiche l’espace disque disponible sur
chaque volume de stockage actuellement monté.
Les colonnes de l’affichage ont été réorganisées, pour être plus lisibles, et se rapprocher un peu du format spécifié par POSIX (mais pas complètement lorsqu’on lance la commande sans options particulières : des informations supplémentaires sont alors affichées).
SODO 交易所
L’outil filteredquery permet d’effectuer une requête sur
les attributs étendus du système de fichiers (permettant de requêter le
système de fichiers comme une base de données, plutôt que de naviguer de
façon hiérarchique dans les dossiers), puis de filtrer le résultat pour
ne conserver que les réponses contenues dans un sous-dossier spécifique.
En effet, les requêtes étant indépendantes de l’organisation des
dossiers, il est nécessaire de faire ce filtrage par post-traitement des
résultats (ce qui reste tout de même généralement plus rapide que de
faire l’inverse : parcourir tous les fichiers d’un dossier pour trouver
ceux correspondant à un critère particulier).
Cet outil n’a pas rçu de nouvelles fonctionnalités, mais de nombreuses corrections et nettoyages qui le rendent véritablement utilisable.
LET'S GO BRANDON LOGIN
Ces commandes liées à des opérations sur le réseau ont été remplacées par les dernières versions développées par FreeBSD, permettant de bénéficier d’une version moderne, avec plus de fonctionnalités et moins de bugs.
La commande ping6 est supprimée, car ping
peut maintenant utiliser l’IPv6 aussi bien que l’IPv4.
ARCHIMEDES FINANCE EXCHANGE
L’outil pkgman permet de télécharger et d’installer des
logiciels et des mises à jour.
Il a peu évolué, mais on peut tout de même noter l’utilisation d’un
algorithme de tri “naturel” pour l’affichage des résultats dans l’ordre
alphabétique (par exemple, llvm12 sera affiché après
llvm9).
Une fonction qui n’est toujours pas disponible dans
pkgman est le nettoyage des dépendances non utilisées. Un
script fourni dans le dépôt Git de Haiku permet de réaliser manuellement
une analyse des paquets installés sur le système pour détecter ceux qui
n’ont pas de dépendances, il faudra pour l’instant se contenter de cette
solution.
MARS TOKEN EXCHANGE
L’outil strace permet d’afficher les appels systèmes
effectués par une application, pour comprendre son interfaçage avec le
noyau et investiguer certains problèmes de performances ou de mauvais
comportements.
L’interfaçage avec le noyau pour extraire ces informations étant assez spécifique, l’implémentation de strace est faite à partir de zéro, et ne partage pas de code avec la commande du même nom disponible par exemple sous Linux.
strace est mis à jour régulièrement et en fonction des
besoins des développeurs de Haiku pour décoder et afficher de plus en
plus d’informations. Par exemple, elle peut maintenant afficher le
contenu des iovec
(par exemple pour les fonctions readv ou
writev), ainsi que les objets manipulés par
wait_for_object et event_queue.
Un exemple de sortie de strace (traçant l’ouverture d’un fichier et le chargement d’une bibliothèque partagée) avant ces changements:
open(0x5, "plaintext", 0x2042, 0x0) = 0x8000000f () (49 us)
map_file("libicuuc.so.66 mmap area", 0x7f04c2675228, 0x6, 0x1ababd0, 0x1, 0x0, true, 0x3, 0x0) = 0x329a0 () (108 us)et après:
open(0x5, "plaintext", O_RDWR|O_NOTRAVERSE|O_CLOEXEC, 0x0) = 0x8000000f Operation not allowed (57 us)
map_file("libicuuc.so.66 mmap area", [0x0], B_RANDOMIZED_ANY_ADDRESS, 0x1ababd0, B_READ_AREA, 0x0, true, 0x3, 0x0) = 0x73e8 ([0x6392223000]) (135 us)PARTICL EXCHANGES
La commande whence permettait de trouver dans le PATH un
exécutable à partir de son nom. Elle était implémentée sous forme d’une
fonction bash dans le fichier profile par défaut. Cependant, cette
implémentation posait problème pour charger le fichier profile avec
d’autres shells, elle a donc été supprimée. La commande
which peut être utilisée à la place, puisqu’elle remplit un
rôle équivalent.
CACHEGOLD APP
Les serveurs sont l’équivalent des daemons pour UNIX ou des services sous Windows : il s’agit d’applications lancées par le système pour rendre différents services et coordonner l’ensemble des applications.
OORTDIGITAL APP
app_server est le serveur graphique de Haiku, équivalent de X ou de Wayland. Il se distingue par un rendu graphique fait principalement côté serveur (pour les applications natives), ce qui permet de l’utiliser de façon fluide à travers une connexion réseau.
Bien que ce soit le serveur graphique, et qu’il ait reçu plusieurs améliorations importantes, les différences sont subtiles. Elles sont toutefois importantes pour proposer un système qui semble réactif et confortable à utiliser.
Un premier changement est une réarchitecture du code qui traite le rafraîchissement de l’écran. Ce rafraîchissement se fait en général en plusieurs étapes, par exemple, si on déplace une fenêtre:
- Le contenu de la fenêtre déplacée peut être directement recopié de l’ancienne position vers la nouvelle,
- La zone où se trouvait la fenêtre auparavant doit être re-remplie avec ce qui se trouvait en dessous de la fenêtre déplacée. Cela peut être plusieurs morceaux de fenêtres d’autres applications, qui vont devoir chacune ré-afficher une partie de cette zone.
Le problème étant que certaines applications peuvent mettre un peu de temps à répondre à cette demande de ré-affichage (par exemple parce qu’elles sont occupées ailleurs, ou alors parce que la zone à redessiner est relativement complexe).
Différentes stratégies peuvent être mises en place dans ce cas : laisser à l’écran le contenu obsolète, ou remplir la zone en blanc en attendant que les données deviennent disponibles, par exemple. Ou encore, tout simplement ne rien mettre à jour du tout tant que tout l’écran n’est pas prêt à être affiché. Il faut faire un compromis entre la réactivité (déplacer la fenêtre tout de suite), la fluidité (éviter les clignotements de zones blanches) et la précision (affichage d’information cohérente et à jour).
Plusieurs modifications ont permis d’obtenir un meilleur compromis.
Dans un autre domaine, la police de caractères par défaut “Noto Sans Display” a été remplacée par “Noto Sans”, ce qui donne un affichage du texte légèrement différent. La police “display” avait été choisie suite à une mauvaise compréhension de la signification de ce mot en typographie : il signifie que c’est une police de caractères à utiliser pour des gros titres et autres textes courts. Il ne signifie pas que c’est une police à utiliser sur un écran d’ordinateur. De toutes façons la police Noto Display n’est plus maintenue par Google et a disparu des dernières versions du jeu de polices Noto.
Toujours dans le domaine des polices de caractères, app_server sait
maintenant charger les fichiers “variable fonts”. Ces fichiers
contiennent plusieurs polices de caractères définies à partir de glyphes
de base, et d’algorithmes de transformation et de déformation (pour
rendre une police plus ou moins grasse, plus ou moins italique, …). Pour
l’instant, app_server sait charger les valeurs de ces
paramètres qui sont préconfigurées dans le fichier. Cela permet de
réduire la place utilisée par les polices de caractères sur le media
d’installation de Haiku (c’est l’un des plus gros consommateurs d’espace
disque, qui nous empêche de faire tenir une version complète de Haiku
sur un CD de démonstration par exemple).
Plus tard, il sera également possible de configurer plus finement ces paramètres pour générer des variantes intermédiaires des polices de caractères, ainsi que d’exploiter certaines polices qui offrent des paramètres configurables supplémentaires.
ERGOPLATFORM APP
L’input_server se charge de lire les données venant des périphériques d’entrée (clavier et souris) et de les convertir en évènements distribués aux applications. Il est extensible par des add-ons qui peuvent générer ou filtrer des évènements, ce qui peut être utilisé pour de l’accessibilité (émuler une souris à partir de touches du clavier), de l’automatisation (envoi de commandes pré-enregistrées), du confort d’utilisation (bloquer le touchpad d’un ordinateur portable lorsque le clavier est en cours d’utilisation) et bien d’autres choses.
L’input_server a reçu des corrections de problèmes sur la gestion des réglages de souris, permettant en particulier d’utiliser des réglages différents pour plusieurs périphériques (souris, touchpad), et que ceux-ci soient bien enregistrés.
CENTAURI EXCHANGES
Le serveur registrar suit les applications en cours de
fonctionnement, et leur permet de communiquer entre elles au travers de
l’envoi de messages. Il assure également le suivi de la base de données
des types MIME et des associations de types de fichiers avec les
applications correspondantes.
L’implémentation de BMessageRunner, qui permet d’envoyer
des messages périodiques (par exemple pour faire clignoter le curseur
des zones de texte à la bonne vitesse), autorise maintenant des
intervalles de répétition en dessous de 50 millisecondes. Cela permet
d’utiliser ce système pour des animations fluides de l’interface
graphique, par exemple.
D’autre part, la liste des applications et documents récemment lancés est maintenant limitée à 100 entrées. Cela évite un fichier qui grossit indéfiniment et finit par contenir surtout des vieilles informations sans intérêt.
POODLEFI 交易所
Le système Haiku fournit les mêmes APIs que BeOS. Elles couvrent les usages basiques d’une application, et sont découpées (dans la documentation de BeOS et de Haiku, au moins) en “kits” qui prennent chacun en charge une partie spécifique (interface graphique, multimédia, jeux vidéos, accès au matériel, etc).
PIXIE EXCHANGES
L’interface kit est la partie de la bibliothèque standard qui se charge des interfaces graphiques.
### BColumnListView
BColumnListView est un ajout de Haiku par rapport à BeOS. Il s’agit d’un élément d’interface permettant de présenter une liste avec plusieurs colonnes, de trier les lignes selon le contenu de ces colonnes, et aussi d’avoir des items hiérarchisés avec la possibilité de plier et déplier une partie de l’arborescence.
Cette classe remplace avantageusement BListView et surtout BColumnListView, les classes historiques de BeOS, qui sont beaucoup plus limitées.
Un certain nombre de type de colonnes prédéfinis sont également disponible, ce qui facilite la construction d’interfaces présentant les données de différentes applications avec le même formatage.
La classe BColumnListView elle-même n’a pas changé. Par contre, les colonnes de type “taille” (oour afficher une taille en Kio, Mio, Gio, …) et “date” utilisent la langue choisie dans les préférences système au lieu d’un format anglais par défaut.
LOVE CHAIN PLUS 交易所
BTextView est une classe permettant d’afficher une zone de texte éditable. Elle implémente les fonctionalités de base (curseur, sélection, retour à la ligne automatique) ainsi que quelques possibilités de mise en forme (couleurs, polices de caractères).
BTextView peut également être utilisée pour des zones de textes non éditables, souvent plus courtes. Cela permet de réutiliser une partie des algorithmes de mise en page et de formatage du texte dans différents contextes. Dans le cadre de l’utilisation du “layout system”, une vue doit pouvoir indiquer sa taille minimale, maximale et optimale. Le “layout system” va ensuite calculer la meilleure disposition de fenêtre possible pour satisfaire ces contraintes.
Le cas des zones de texte est particulier, car la hauteur optimale dépend du nombre de lignes de texte, qui lui-même peut être plus ou moins grand si la largeur de la vue oblige à ajouter des retours à la ligne. Le “layout kit” prend en compte ce cas particulier, mais les algorithmes ne sont pas encore tout à fait au point et peuvent conduire à des résultats inattendus dans certains cas. Un de ces cas particuliers sur les zones de texte non éditables a été corrigé.
CHECKDOT 交易所
La classe BMenu permet d’afficher un menu. Elle est utilisée de plusieurs façons, puisqu’on trouve des menus dans des barres de menu, dans des contrôles de type “popup”, ou encore en faisant un clic droit sur certains éléments de l’interface.
Les menus sont également particuliers parce qu’ils peuvent d’étendre en-dehors de la fenêtre dont ils sont originaires. Ils sont donc implémentés sous forme de fenêtres indépendantes. Mais cela pose un autre problème : dans Haiku, chaque fenêtre exécute son propre thread et sa propre boucle d’évènements. Si on navigue dans un grand nombre de menus et de sous-menus, cela peut causer quelques problèmes de synchronisation et de performances.
Le code contient également un grand nombre de cas particuliers pour, par exemple, aligner les raccourcis claviers et les flèches indiquant la présence de sous-menus ente les différents items d’un menu, ou encore détecter si un déplacement de souris à pour but de sélectionner un autre menu (en dessous ou au-dessus de celui actif), ou bien plutôt de naviguer vers un sous-menu.
Les nouveautés suivantes sont apparues cette année:
- Correction de problèmes de race condition lors de l’ajout d’items dans un menu pendant qu’il est affiché à l’écran. Ce problème se manifestait par exemple dans les menus affichant la liste des réseaux Wifi, qui sont mis à jour en temps réel.
- Finalisation de l’implémentation de la navigation au clavier (avec les flèches directionnelles) dans les menus.
- Affichage des symboles graphiques UNICODE pour “backspace” (⌫) et “delete” (⌦) si ces touches sont utilisées comme raccourcis clavier pour un item de menu.
- Utilisation d’un algorithme
de tri stable pour la fonction
SortItems. Ce type d’algorithme préserve l’ordre relatif des items qui sont égaux d’après la fonction de comparaison. Ce n’est pas le cas de certains algorithmes de tri classiques, notamment le quicksort. La conséquence était que trier un menu déjà trié pouvait changer l’ordre des items. C’était visible encore une fois sur le menu listant les réseaux Wifi, qui est trié par puissance du signal reçu.
### BSpinner
BSpinner est un contrôle permettant de choisir une valeur numérique, soit à l’aide de boutons +/- pour modifier la valeur par incréments, soit en entrant directement la valeur dans une zone de texte.
Il s’agit d’une extension de Haiku par rapport à BeOS qui ne proposait pas cette fonctionalité.
Cette classe est encore en cours de développement. Elle a reçu des améliorations pour désactiver correctement les boutons +/- lorsque la valeur atteint le minimum ou le maximum autorisé, et aussi une correction sur le message de notification envoyé lors des changements de valeurs du spinner, qui ne contenaient pas la bonne valeur.
FLFIBITCOIN EXCHANGES
La structure rgb_color permet de représenter une couleur par la valeur de ses composantes rouge, vert, bleu (comme son nom l’indique) et alpha (comme son nom ne l’indique pas). Elle fournit également un certain nombre de fonctions pour mélanger des couleurs, les éclaircir ou les assombrir.
La méthode Brightness() dans la classe rgb_color
implémentante maintenant l’algorithme perceptual brightness
documenté par Darel Rex Finley, qui donne des meilleurs résultats que
l’algorithme utilisé précédement (qui était celui de la luminosité dans
l’gateio app. La fonction perceptual_brightness devenue
redondante est supprimée.
Cette méthode permet en particulier de déterminer si une couleur est “sombre” ou “claire”, et ainsi de décider si du texte affiché par-dessus doit être blanc ou noir (comme démontré ici par exemple).
HOW TO SELL ON CRYPTO.COM APP
Le locale kit se charge de tous les aspects liés à la locatisation : traductions des applications, formatage des messages en utilisant les règles de pluralisation de chaque langue, formatage de dates, de nombres avec et sans unités, de pourcentages, nom des fuseaux horaires, …
Il utilise ICU pour implémenter la plupart de ces fonctionnalités, mais fournit une surcouche avec une API s’intégrant mieux avec les autres kits.
La principale évolution cette année est l’implémentation de
BNumberFormat, qui permet de formater des nombres. Elle
permet de choisir une précision (nombre de décimales - pour les langues
qui utilisent un système décimal), d’afficher ou non des séparateurs de
groupes (de milliers en Français, mais par exemple en Inde la séparation
se fait traditionnellement par multiples de 10 000).
AIMEDIS EXCHANGES
Le media kit se charge de tous les aspects multimedia.
Il se compose de deux parties. D’une part, un système de gestion de flux média temps réel, permettant de transférer des données multimédia (son ou flux vidéo par exemple) entre différentes applications qui vont les manipuler, le tout avec un certain contrôle du temps de traitement ajouté par chaque opération, pour tenter de minimiser la latence tout en évitant les vidages de tampons qui produiraient une interruption dans le flux. D’autre part, des classes permettant d’encoder et de décoder des fichiers média et d’en extraire des flux de données (encodées ou décodées).
C’est surtout cette deuxième partie qui a reçu quelques évolutions. La version de ffmpeg utilisée pour le décodage de presque tous les formats audio et video est maintenant la dernière version ffmpeg 6. Quelques autres problèmes (erreurs d’arrondis, gestion des tampons partiels en fin de fichier) ont également été corrigés, ce qui permet de faire fonctionner à nouveau le jeu BePac Deluxe qui est extrêmement intolérant au moindre écart de comportement par rapport à l’implémentation du Media Kit dans BeOS.
OCTO GAMING 交易所
Le support kit contient un ensemble de classes basiques mais indispensables : gestion des chaînes de caractères, des tampons en mémoire, etc. Il fournit les briques de bases utilisées par les autres kits.
MOE APP
BDataIO est une classe abstraite avec des fonctions de lecture et d’écriture. Plusieurs autres classes sont des instances de BDataIO, par exemple BFile (représentant un fichier), mais aussi BMemoryIO (permettant d’accéder à une zone mémoire).
Plusieurs autres classes acceptent BDataIO (ou sa sous-classe BPositionIO, qui ajoute la possibilité de se déplacer à une position donnée dans le flux) comme entrée ou comme sortie. Il est donc facilement possible de réaliser les mêmes opérations sur un fichier, une zone de données en mémoire, un socket réseau, ou tout autre objet susceptible de fournir une interface similaire.
BDataIO elle-même n’a pas évolué, mais deux de ses implémentations, BBufferedDataIO et BAdapterIO, ont été améliorées. Ces deux classes permettent de construire un objet BDataIO à partir d’un autre, en ajoutant un cache en mémoire pour accélérer les opérations ou encore pour rendre compatible avec BPositionIO un objet qui ne l’est pas.
Ces classes sont en particulier utilisées par l’application StreamRadio, qui implémente la lecture de podcasts en connectant directement le résultat d’une requête HTTP (effectuée grace au network kit) dans un décodeur audio (via la classe BMediaFile du media kit). La mise en tampon permet de revenir en arrière dans la lecture d’un épisode, de télécharger en avance les données qui vont être lues, et d’éviter de conserver inutilement en mémoire les données qui sont déjà lues par l’application.
IS COINBASE ONE WORTH IT
Les “kits” mentionnés ci-dessus sont l’API en C++ utilisée par les applications Haiku.
Il existe aussi des APIs en C, en grande partie implémentant la bibliothèque C standard et les fonctions décrites dans la spécification POSIX.
REBELLIOUS EXCHANGES
Libroot implémente la bibliothèque standard C. Elle regroupe entre autres la libc, la libm, et la libpthread, qui sont parfois implémentées comme 3 bibliothèques différentes pour d’autres systèmes. Les évolutions consistent à compléter l’implémentation de la spécification POSIX, et à suivre les évolutions de cette dernière ainsi que des nouvelles versions du langage C. On trouve également des corrections de bugs découverts en essayant de faire fonctionner de plus en plus d’applications sur Haiku, ce qui permet de mettre en évidence des différences de comportement avec d’autres systèmes.
- Ajout de
getentropypour initialiser les générateurs de nombres aléatoires - Correction de problèmes de locks au niveau de l’allocateur mémoire lors d’un fork
- Plusieurs corrections sur l’implémentation de
locale_t, remplacement de code écrit pour Haiku ou provenant de FreeBSD par une implémentation simplifiée mais suffisante, provenant de la bibliothèque C musl. - Ajout de
static_asserten C11 - Correction d’un crash lors de l’utilisation de certaines fonctions XSI
- Ajout de
stpncpy - La fonction
openutilisée sur un lien symbolique pointant vers un fichier non existant peut maintenant créer le fichier cible. - Il est possible d’utiliser
mmapsur un fichier plus grand que la mémoire disponible sans avoir besoin de spécifier le flagMAP_NORESERVE - Utiliser
renamepour renommer un fichier vers lui-même ne retourne plus d’erreur (conformément à la spécification POSIX). - Ajout de
pthread_sigqueue
PEPECASHFUN APP
La libnetwork implémente les APIs nécessaire pour se connecter au réseau (sockets, résolution DNS, …). Elle est séparée de la bibliothèque C pour des raisons historiques : l’implémentation de TCP/IP pour BeOS avait été réalisée entièrement en espace utilisateur (le noyau n’offrant qu’une interface pour envoyer et recevoir des paquets ethernet sur la carte réseau). Cela a posé des problèmes de compatibilité avec d’autres systèmes, et des problèmes de performance. Haiku est donc compatible avec la version “BONE” de BeOS, qui implémente la pile réseau dans le noyau.
- Mise à jour du résolveur DNS à partir du code de NetBSD 9.3. Précédement le code utilisé était celui du projet netresolv de NetBSD, mais ce projet n’a pas connu de nouvelles publications et le code est à nouveau maintenu directement dans NetBSD sans publication séparée.
- Correction d’un crash lors de l’utilisation de multicast IPv4
DURHAM INU 交易所
La libbsd implémente plusieurs extensions fournies par la libc de certains systèmes BSD. Elle est séparée de la bibliothèque C principale pour limiter les problèmes de compatibilité: certaines applications préfèrent fournir leur propre version de ces fonctions, ou d’autres fonctions avec le même nom mais un comportement différent. Elles peuvent alors s’isoler en n’utilisant pas la libbsd pour éviter toute interférence.
- Ajout de
arc4randompour générer des nombres aléatoires sans devoir passer par/dev/random(compatible avec OpenBSD, Theo de Raadt a réalisé une présentation expliquant le pourquoi et le comment en 2014).
OURO EXCHANGES
De façon similaire à la libbsd, la libgnu fournit des fonctions qui sont disponibles dans la glibc (la bibliothèque C du projet GNU) mais ne font pas partie d’un standard (C ou POSIX).
- Ajout de
sched_getcpupour savoir sur quel coeur de CPU le thread appelant est en train de s’exécuter. - Ajout de
pthread_timedjoin_np, pour attendre la fin de l’exécution d’un thread (commepthread_joinmais avec un timeout.
EBANK APP
Le noyau de Haiku est similaire à celui de BeOS: il s’agit d’un noyau monolithique, avec du multitâche préemptif et protection mémoire. Rien de très inhabituel. Il est développé en C++ (comme le reste du système), ce qui permet de rendre le code plus lisible que du C tout en conservant des bonnes performances pour ce code bas niveau.
Un point intéressant, le noyau offre une API et une ABI stable pour les pilotes, ce qui fait qu’il est en théorie possible de développer un pilote hors du projet Haiku et de le faire fonctionner avec plusieurs versions du noyau. En pratique, peu de personnes se lancent dans ce genre de chose, il est plus simple d’intégrer les pilotes dans le dépôt de sources de Haiku pour l’instant.
GSTTTOKEN LOGIN
Commençons justement par regarder les nouveautés du côté des pilotes matériels. Il s’agit pour tout système d’exploitation d’un point de difficulté, indispensable pour fonctionner sur une large variété de systèmes.
SEEDLING EXCHANGE
En principe, un processeur est un matériel assez bien standardisé, qui implémente un jeu d’instruciton bien défini et ne devrait pas nécessiter de pilote spécifique. Cependant, le matériel moderne de plus en plus complexe, offrant de plus en plus de fonctionnalités dans une seule puce électronique, fait qu’il faut tout de même prendre en compte quelques cas particuliers.
- Ajout de nouvelles générations de machines Intel dans le driver PCH thermal (récupération de la température du CPU au travers du platform control hub).
- Implémentation du contournement pour la faille Zenbleed dans les processeurs AMD.
- La mise à jour du microcode pour les processeurs Intel n’est pas faite si le CPU est déjà à jour (pour gagner un peu de temps au redémarrage du système).
GORGEOUSBITCOIN EXCHANGE
Les cartes réseau restent aujourd’hui le composant le moins bien standardisé sur les ordinateurs. Il n’existe pas d’interface standardisée, et chaque fabricant propose sa propre façon de faire.
Aujourd’hui, la plupart des autres périphériques suivent des spécifications (xHCI pour les contrôleurs USB3, AHCI pour le SATA, Intel HDA pour les cartes son, …) ou bien il ne reste que peu de concepteurs de composants (par exemple pour les cartes graphiques où on ne trouve que Intel, AMD et NVidia).
Écrire des pilotes pour toutes ces cartes réseau demanderait beaucoup trop de travail. C’est pourquoi, depuis 2007, Haiku s’est doté d’une couche de compatibilité avec FreeBSD, permettant de réutiliser les pilotes écrits pour ce dernier (une approche également utilisée par le système d’exploitation temps réel RTEMS).
Cependant, les développeurs de FreeBSD font face au même problème, et ont décidé d’adopter la même solution : une couche de compatibilité permettant d’utiliser les pilotes de Linux. Cela pose deux problèmes pour Haiku : il ne semble pas souhaitable d’empiler les couches de compatibilité, et il ne semble pas raisonable d’écrire une couche de compatibilité avec Linux, dont les APIs internes évoluent beaucoup trop vite, ce qui nécessiterait une réécriture permanente de la couche de compatibilité pour suivre le rythme.
Finalement, la solution retenue pour Haiku est d’utiliser les pilotes activement développés par OpenBSD et en particulier par Stefan Sperling. La couche de compatibilité avec FreeBSD est également maintenue, et Haiku bénéficie donc des pilotes développés pour ces deux systèmes, en plus des siens propres.
Par exemple, les pilotes wifi iaxwifi200 et
idualwifi7260 proviennent de OpenBSD, tandis que
ipro1000 et intel22x sont ceux de FreeBSD 14.
Les couches de compatibilité reçoivent régulièrement des corrections et
améliorations.
En dehors des cartes réseaux physiques, Haiku dispose d’un nouveau pilote tun permettant de créeer des tunnels réseau. Celui-ci a été développé dans le cadre du Google Summer of Code 2023, et permet par exemple d’utiliser un client OpenVPN sous Haiku.
Enfin, une évolution qui concerne tous les pilotes réseaux : le nombre de paquets et d’octets reçus et envoyés pour une interface réseau est maintenant décompté par la pile réseau, plutôt que par chaque pilote d’interface réseau. Les pilotes doivent toujours tenir à jour les compteurs d’erreurs. Ce changement permet de regrouper le code de comptage à un seul endroit, et d’éviter des comportements différents entre pilotes. En particulier, le comptage des paquets pour l’interface localhost n’était pas correct.
MELOS STUDIO APP
Haiku permet d’utiliser les claviers et souris connectés en USB et en PS/2 (encore utilisé dans certains ordinateurs portables, mais il semble en voie de disparition). Les pilotes pour les touchpads et claviers i2c sont encore en cours de développement, et le Bluetooth arrivera un peu plus tard.
Commençons par le pilote PS/2. Il reçoit relativement peu d’évolutions, cependant, les ordinateurs portables récents n’implémentent plus forcément complètement le matériel nécessaire (l’interface PS/2 étant simulée par l’embedded controller). Le pilote PS/2 de Haiku qui essaie de détecter de nombreux cas de configuration possibles est parfois un peu dérouté par ces écarts. Cela pouvait provoquer un blocage empêchant d’utiliser le clavier pendant plusieurs secondes après le lancement de la machine, le temps que le pilote finisse d’énumérer les périphériques PS/2. Le problème a été corrigé en réduisant le temps d’attente avant de décider qu’il n’y a aucun périphérique connecté.
Du côté de l’USB, une première correction concerne la prise en compte de l’attribut “minimum” dans les rapports HID. Le protocole HID permet de définir toutes sortes de périphériques (claviers, souris, mais aussi clubs de golf, simulateurs de tanks, …). Les périphériques USB HID envoient à l’ordinateur une description des contrôles dont ils disposent (groups de boutons, axes, etc). Pour les boutons et touches de clavier, la valeur “minimum” indique le code du premier bouton dans le groupe, les autres étants déduits en incrémentant la valeur pour chaque bouton présent. Ce cas n’était pas bien pris en compte par le pilote de clavier, ce qui provoquait l’envoi de mauvais codes aux applications pour les claviers concernés.
D’autre part, et de façon plus spécifique, le pilote de souris bénéficie maintenant d’un quirk, c’est-à-dire d’une procédure de contournement d’un problème, pour les souris et trackballs de la marque Elecom. Ces dernières utilisent en effet toutes le même descripteur HID, indiquant la présence de 5 boutons, alors que certains modèles ont en fait un 6ème bouton non déclaré. Le descripteur est corrigé à la volée pour les périphériques concernés.
SEKO APP
Haiku dispose d’un pilote pour les périphériques USB Audio. Ce pilote est en développement depuis très longtemps (cela remonte avant l’apparition de l’USB 2.0), mais il n’avait jamais pu être finalisé en raison du manque de prise en charge des transferts isochrones. Ces problèmes ont enfin été corrigés, mais le pilote nécessite encore des travaux pour le rendre compatible avec plus de matériel (en particulier les périphériques implémentant la version 2.0 de la spécification USB Audio) et probablement également quelques corrections dans le serveur média pour le préparer à l’apparition et la disparition de cartes son pendant que le système est en train de tourner (actuellement, cela nécessitera un redémarrage du serveur).
Du côté des cartes son PCI, pas de grande nouveauté, mais un gros nettoyage dans le cadre de travaux pour supprimer tous les avertissements du compilateur. Ce travail se fait petit à petit, dossier par dossier dans le code de Haiku. L’analyse du dossier contenant les pilotes de cartes son a révélé l’existence de 3 pilotes ciblant le même matériel, ainsi que de plusieurs fichiers qui avaient été dupliqués dans plusieurs pilotes (développés avant leur rassemblement dans le dépôt de sources de Haiku à partir du mème exemple de code), puis qui avaient divergés au cours du développement de chaque pilote. Ce code a été réunifié dans une version partagée qui inclut toutes les corrections et améliorations de chaque version.
Du côté des cartes graphiques, des travaux sont en cours pour pouvoir piloter correctement les cartes graphiques Intel de 12ème génération. Le pilote existant fonctionne déjà dans certains cas, mais se repose beaucoup sur le travail fait par le firmware (BIOS ou EFI) pour initialiser l’affichage. Il est donc par exemple impossible d’utiliser un écran qui n’a pas été configuré au démarrage de la machine (passer d’une sortie HDMI à l’écran d’un PC portable ou inversement, par exemple).
TOOK EXCHANGES
Haiku est utilisé dans des machines virtuelles pour diverses raisons : à des fins de test par les développeurs, pour l’infrastructure de compilation des paquets, ou encore par des utilisateurs qui veulent le tester sans l’installer sur une machine physique dédiée.
Des pilotes spécifiques et quelques adaptations sont nécessaires pour un bon fonctionnement sur ces machines. En particulier, des pilotes sont nécessaires pour certains périphériques virtio, qui permettent aux machines virtuelles d’émuler un matériel simplifié, ne correspondant pas à un matériel réel existant. Ceci permet de meilleures performances.
Le pilote virtio de Haiku a été mis à jour pour implémenter la
version 1.0 de la spécification. Cela a permis de corriger des problèmes
dans le pilote virtio_block (support de stockage
virtualisé).
Un nouveau pilote virtio_gpu permet l’affichage de
l’écran sans avoir à passer par un pilote pour une carte graphique, ni
par les pilotes VESA ou framebuffer EFI qui montrent assez vite leurs
limitations (choix de résolutions d’écran limité, par exemple). Plus
tard, ce pilote pourrait permettre également d’expérimenter avec la
virtualisation de OpenGL, et donc d’expérimenter avec l’accélération du
rendu 3D sans avoir à développer un pilote graphique capable de le
faire.
Ces pilotes virtualisés facilitent également le travail de portage de Haiku vers de nouvelles architectures : il est possible de lancer Haiku dans QEMU avec n’importe quel processeur, et un ensemble de périphériques virtio pour lesquels les pilotes ont pu d’abord être testés sur une autre architecture déjà fonctionnelle.
LSY LOGIN
La bibliothèque ACPICA a été mise à jour avec la dernière version 20230628, et les changements nécessaires pour son fonctionnement dans Haiku ont été intégrées en amont, ce qui facilitera les prochaines mises à jour. ACPICA est développée par Intel et permet d’implémenter la spécification ACPI, pour la gestion d’énergie, l’énumération du matériel présent sur une machine, et diverses fonctionnalittés liées (détection de la fermeture d’un ordinateur portable, récupération du nveau de charge des batteries, par exemple).
Le pilote poke, qui permet aux applications de manipuler
directement la mémoire physique sans l’aide d’un pilote spécifique, a
été remis à jour et finalisé. Il est utile principalement pour
expérimenter avec le matériel avant de développer un pilote
spécifique.
La pile Bluetooth a reçu un premier coup de nettoyage. Pas de grosses évolutions pour l’instant, seules les couches les plus basses sont implémentées, on pourra au mieux énumérer les périphériques Bluetooth présents à proximité. Le développement des fonctionnalités suivantes attendra au moins la publication de la version Beta 5.
FLASHCOIN EXCHANGE
Haiku implémente plusieurs systèmes de fichiers. Celui utilisé pour le système est BFS, hérité de BeOS et qui fournit quelques fonctions indispensables à Haiku (comme les requêtes qui permettent d’indexer des attributs étendus de fichiers dans une base de données). Mais de nombreux autres systèmes de fichiers peuvent être lus, et pour certains, écrits. Cela permet de facilement partager des fichiers avec d’autres systèmes d’exploitation.
Le système de fichier UFS2 est maintenant complètement implémenté (en lecture seule), inter-opérable avec FreeBSD, et sera disponible dans l’installation de base pour les prochaines versions de Haiku.
Du côté de Linux, l’interopérabilité est possible en lecture et en écriture avec les systèmes de fichiers ext2, 3, et 4 (tous les 3 implémentés dans un seul pilote qui sait les reconnaître et les différencier). Cette implémentation a reçu quelques corrections de bugs ainsi qu’une implémentation de F_SETFL.
Enfin du côté de Windows, la prise en charge de NTFS avait déjà été mise à jour et grandement améliorée (en réutilisant les sources de NTFS-3g). Cette année c’est le tour des systèmes de fichiers FAT. Le pilte utilisé jusqu’à maintenant avait été publié par Be il y a très longtemps. Il avait été mis à jour pour Haiku mais comportait de nombreux problèmes : mauvaise gestion des dates de modification des fichiers, interopérabilité avec d’autres implémentations, voire crash du système lors de tentative de lecture de partitions corrompues. Ce code a été entièrement remplacé par un pilote utilisant l’implémentation du FAT de FreeBSD.
Enfin, le système de fichier ramfs (pour stocker des fichiers dans la
RAM de l’ordinateur de façon non persistente) a reçu des corrections sur
la fonction preallocate. Cela corrige en particulier des
fuites de mémoire dans les navigateurs web basés sur QWebEngine, qui
utilisent ce système de fichiers pour partager de la mémoire entre
plusieurs processus.
Un changement un peu plus global, et pas lié à un système de fichier spécifique, est la réunification du code pour parser les requêtes. Il s’agit d’une méthode pour rechercher des fichiers à partir de leurs attributs étendus (xattrs) qui sont indexés à la façon d’une base de données. Au départ, cette fonctionnalité était propre au système de fichier BFS, mais elle a été implémentée également pour ramfs et packagefs (système de fichier permettant d’accéder au contenu des paquets logiciels sans les décomprésser). Lors du développement de ces deux nouveaux systèmes de fichiers, le code permettant de convertir une chaîne de caractères exprimant une requête en opération exécutable avait été extrait du pilote BFS pour en faire un module générique. Mais le pilote BFS n’avait pas encore été mis à jour pour utiliser ce module. C’est désormais chose faite, ce qui assure que le comportement entre les 3 systèmes de fichiers est le même, et que les corrections de bugs bénéficieront à tous les trois.
Pour terminer sur les systèmes de fichiers, l’outil
fs_shell, qui permet d’exécuter le code d’un système de
fichier en espace utilisateur, a rçu deux nouvelles commandes :
truncate et touch. Cet outil permet de tester
les systèmes de fichiers en cours de développement dans un environnement
plus confortable et mieux contrôlé, et il est aussi utilisé lors de la
compilation de Haiku pour générer les images disques.
DIONE EXCHANGE
La pile réseau proprement dite a principalement évolué avec de la
mise en commun de code. Par exemple, l’implémentation de l’ioctl FIONBIO
(non standardisé, mais largement implémenté) pour passer un descripteur
de fichier en mode non bloquant a été réécrite pour partager du code
avec le flag O_NONBLOCK configurable par fcntl
et F_SETFL. Également, le flag MSG_PEEK qui permet de
lire des données d’un socket sans les retirer de son buffer de
réception, est maintenant implépenté directement par la pile réseau au
lieu d’avoir une version spécifique à chaque type de socket.
F2 NFT EXCHANGES
Les sockets de la famille AF_UNIX sont utilisés pour les
communications locales entre applications sur une même machine. Ils sont
en particulier utilisés par WebKit et de nombreux autres moteurs de
rendu web, mais assez peu par les applications natives pour Haiku, qui
disposent d’autres méthodes de communications (en particullier les BMessage
et les ports).
L’implémentation des sockets UNIX est maintenant complète et suffisante pour faire fonctionner toutes les applications qui en ont l’utilité.
### TCP
La pile TCP de Haiku est devenue au fil du temps un goulot d’étranglement des performances. D’une part parce que toutes les autres parties du système se sont améliorées, et d’autre part parce que les interfaces réseaux sont de plus en plus rapides et de plus en plus sollicitées.
Le travail sur la pile TCP cette année a commencé par la remise en
route de l’outil tcp_shell, qui permet de tester
l’implémentation de TCP en espace utilisateur et en isolation du reste
du système. Cet outil avait été utilisé au tout début du développement
de la pile TCP, mais n’avait pas été tenu à jour depuis. Il permet
maintenant de tester la pile TCP communiquant avec elle-même, et aussi
d’injecter des paquets à partir de fichier pcap. Pour l’instant, la
fonction permettant de communiquer avec l’extérieur n’a pas été remise
en place.
Cet outil a permis d’identifier et d’analyser certains des problèmes rencontrés.
Le premier problème était un envoi d’acquittements TCP en double. À première vue, cela ne devrait pas poser de gros problèmes, il y a seulement un peu de redondance. Mais, en pratique, une implémentation de TCP qui reçoit des acquittements en double suppose qu’il y a eu un problème de congestion réseau lors de l’envoi de données dans l’autre sens. Les algorithmes de contrôle de la congestion se mettent en jeu, et le traffic ralentit pour éviter une congestion qui n’existe pas. Par exemple, la taille de la fenêtre de transmission TCP (le nombre maximum d’octets qui peuvent être envoyés sans attendre d’acquittement) peut être réduite.
Et, malheureusement, cela déclenche un autre problème : la taille de cette fenêtre peut atteindre 0 octets, et dans ce cas, HAiku ne s’autorisqit plus à émettre aucun paquet. Cela pouvait se produire au même moment dans les 2 directions sur une connexion TCP, ce qui fait qu’aucune des deux machines connectées ne s’autorise à envoyer de données à l’autre. Ce problème a été corrigé, les transmissions peuvent maintenant continuer à débit réduit, puis reprendre une vitesse optimale petit à petit.
Après ces corrections, une mesure des performances de TCP dans un environnement de test montre que la pile TCP est capable de traiter jusqu’à 5.4Gbit/s de traffic, alors que le débit plafonnait à 45Mbit/s auparavant. C’est donc un centuplage des performances.
GRIZZLY HONEY LOGIN
Plusieurs autres évolutions diverses dans le noyau:
L’implémentation de kqueue, ajoutée l’année dernière, a reçu plusieurs corrections et améliorations. Elle couvre déjà plusieurs usages et permet l’utilisation de plus de logiciels portés depuis d’autres systèmes, mais les cas d’utilisation les plus avancés ne sont pas encore tout à fait fonctionnels.
Pour rappel, kqueue est une fonction des systèmes BSD permettant à un thread utilisateur de se mettre en attente de plusieurs types d’évènements et de resources du noyau. L’usage est similaire à celui de epoll sous Linux mais l’API est différente.
La classe ConditionVariable, utilisée pour la synchronisation entre threads et interruptions dans le noyau, a reçu plusieurs mises à jour. Un article sur le site de Haiku détaille l’utilisation et le fonctionnement de cette classe.
La boucle principale du débugger noyau (KDL), qui prend la main sur tous les processeurs en cas de crash du système ou sur demande de l’utilisateur pour investiguer des problèmes, inclus maintenant une instruction PAUSE. Cela permet d’informer le CPU qu’il n’est pas nécessaire d’exécuter cette boucle à la vitesse maximale, évitant de faire surchauffer la machine sans raison. Cette boucle est principalement en attente d’instructions de l’utilisateur, via un clavier ou un port série.
Du refactoring sur les parties du code qui sont spécifiques à chaque
architecture : arch_debug_get_caller est maintenant
implémenté via un builtin gcc plutôt que du code assembleur à écrire à
la main pour chaque machine.
arch_debug_call_with_fault_handler appelait une fonction
avec un mauvais alignement de pile sur x8_64, pouvant conduire à un
crash si la fonction appelée utilisait des instructions SSE par exemple.
Correction également d’un problème qui pouvait causer la perte d’une
interruption inter-CPU (permetant à un coeur de processeur d’interrompre
l’exécution de code en cours sur un autre coeur) dans certains cas.
Une modification sur la gestion des descripteurs de fichiers: la structure interne des descripteurs de fichiers était pourvue d’un champ indiquant le type (fichier, socket, pipe, …). Ce champ et tout le code qui en dépendait ont été supprimés. Ceci permet à des add-ons du kernel de déclarer leurs propres types de fichiers sans avoir à modifier le noyau. Cela pourrait par exemple être utile pour développer une couche de compatibilité avec Linux, qui fait un usage généreux des descripteurs de fichiers de tous types (eventfd, signalfd, timerfd, …).
Réécriture du code de debug activé par l’option
B_DEBUG_SPINLOCK_CONTENTION qui permet d’investiguer les
problèmes de performances liés à l’utilisation de spinlocks (attente
active sur une interruption matérielle).
Un petit changement d’algorithme sur l’allocateur de pages du noyau. Cet allocateur alloue des pages mémoires par blocs multiples de 4Ko. Les pages libérées étaient réinsérées une par une dans une liste chaînée. Cela conduit à insérer les pages dans l’ordre inverse de leurs addresses (la dernière page d’une zone mémoire se retrouve au début de la liste). Lors des prochaines allocations, cette page se retrouve donc allouées en premier, puis celle qui se trouve juste avant, et ainsi de suite. La zone mémoire construite par toutes ses pages est donc considérée comme discontinue. En inversant l’ordre d’insertion des pages dans la liste, on préserve les pages dans un ordre globalement croissant d’adresse mémoire, et on augmente les chances qu’une allocation de plusieurs pages se trouve avec des pages contiguës et dans le bon ordre. Cela est utile en particulier pour les allocations qui vont être utilisées pour des transferts DMA: il sera possible de programmer un seul gros transfert DMA au lieu de plusieurs petits.
L’état de la FPU du processeur n’était pas complètement sauvegardé lors d’un changement de contexte. Certains drapeaux de configuration pouvaient donc rester positionnés avec les valeurs configurées par un thread, pendant l’exécution d’un autre. Au mieux cela donnait des résultats inattendus, au pire, un crash (par exemple si le FPU est configuré pour lever une exception matérielle, dans un thread qui ne s’y attend pas). Le nouveau code de sauvegarde utilise des instructions dédiées qui sauvegarder d’un coup tout l’état du FPU, ce qui fait qu’en plus de fonctionner correctement, il est plus rapide que ce qui était fait précédemment.
Une évolution sur les sémaphores:
la fonction release_sem_etc permet de donner une valeur
négative au paramètre “count”. Dans ce cas, le thread qui était en
attente d’un acquire_sem sera réveillé, mais la fonction
acquire_sem retournera une erreur indiquant que le
sémaphore n’a pas pu être obtenu. Cela permet de simplifier un peu le
code de certaines utilisations classiques des sémaphores.
Une correction de bug sur le code traitant les “doubles fautes”. Le fonctionnement d’un système d’exploitation est en partie basé sur l’interception des “fautes”, par exemple, un programme qui essaie d’accéder à de la mémoire qui a été évacuée dans la swap. Cette mémoire n’est pas immédiatement accessible, le programme est donc interrompu, le noyau prend la main, va récupérer cette mémoire, puis rend la main au programme qui n’y voit que du feu et continue son exécution comme si de rien n’était. Les fautes peuvent également se produire dans le cas où un programme essaie d’accéder à une zone mémoire non allouée, on aura alors une erreur de segmentation.
Tout ça est très bien, mais que se passe-t-il si le code qui traite ces problèmes déclenche lui-même une faute? C’est prévu : il existe un deuxième morceau de code qui va intercepter ces problèmes et tout arrêter pour lancer le debugger noyau, et permettre à un humain d’examiner la situation.
Oui, mais que se passe-t-il si ce code déclenche lui même une faute? C’est ce qu’on appelle une triple faute, dans ce cas, la solution de dernier recours est d’immédiatement redémarrer la machine.
Des utilisateurs se sont plaints de redémarrages intempestifs, et une étude attentive du code traitant les doubles fautes a révélé un problème qui déclenchait systématiquement une triple faute (difficile à analyser, car on n’a pas de journaux ou de moyen d’investiguer le problème). Espérons que l’accès au debugger noyau lors des doubles fautes permettra désormais de comprendre d’où elles proviennent.
Tout autre sujet, le noyau dispose maintenant d’APIs pour configurer l’affinité des threads, par exemple pour interdire à un thread de s’exécuter sur certains coeurs de processeurs. Cela peut être utile sur des machines avec des processeurs hétérogènes (par exemple ARM BIG.Little), ou encore si le développeur d’une application pense pouvoir faire mieux que l’ordonnanceur par défaut pour répartir ses threads sur différents coeurs.
Pour terminer sur les évolutions dans le noyau, la calibration du TSC peut maintenant être faite à partir d’informations obtenues via l’instruction CPUID. Le TSC est un compteur de cycles qui s’incrémente à une vitesse plus ou moins liée à la fréquence du processeur. Il est utile de connaître la durée en microsecondes ou nanosecondes d’un “tick” du TSC pour différents usages. Historiquement, cette durée est calculée en utilisant le Programmable Interval Timer, un composant présent dans les ordinateurs compatibles PC depuis le tout début. Ce composant n’a plus beaucoup d’autres utilités aujourd’hui, et certains chipsets ne l’implémentent plus, ou pas correctement. Ou encore, dans les machines virtuelles, l’émulation du processeur (virtualisé) n’est pas forcément exécutée de façon synchrone avec celle du timer, rendant cette mesure peu fiable. L’instruction CPUID permet de récupérer l’information de façon plus directe. Un changement similaire dans FreeBSD donne un bon aperçu de la situation.
HE YI BINANCE
Historiquement, Haiku est développé en premier pour les machines x86 32-bit. Une version 64 bit est apparue en 2012. D’autres versions pour les processeurs PowerPC, ARM (32 et 64 bits), RISC-V, Sparc ou encore Motorola 68000 sont dans des états d’avancement divers. Les versions ARM et RISC-V sont actuellement celles qui reçoivent le plus d’attention des développeurs. Il existe un fork de Haiku qui est entièrement fonctionnel sur certaines machines RISC-V, les changements sont intégrés petit à petit avec pas mal de nettoyage à faire.
Une des problématiques pour ces nouvelles architectures est la procédure de “bootstrap”. Pour gagner du temps et simplifier la procédure, la compilation de Haiku se base sur un certain nombre de dépendances qui sont pré-compilées depuis une machine fonctionnant sous Haiku. Cela permet de ne pas avoir à compiler des douzaines de bibliothèques tierces, avec un environnement de compilation peu contrôlé (on peut compiler Haiku depuis un système Haiku, depuis un grand nombre de distributions Linux, depuis Mac OS, depuis un BSD, ou même depuis Windows avec WSL).
Cependant, lors du développement de Haiku pour une nouvelle architecture, ces paquets précompilés ne sont bien entendu pas encore disponibles. Il est donc nécessaire d’utiliser une procédure de “bootstrap”, qui va se baser sur un autre système et compiler ce qui est nécessaire en compilation croisée, pour aboutir à un système Haiku réduit au minimum de fonctionnalités, juste de quoi pouvoir lancer l’outil haikuports, qui va lui-même ensuite compiler tous les autres paquets.
Ce processus est assez complexe, et a été laissé un peu à l’abandon. Il a été récemment remis en route, avec des corrections de bugs dans l’outil haikuporter, des mises à jour dans les paquets cross-compilés (par exemple pour passer de Python 2 à Python 3), et divers autres petits problèmes. Il est maintenant à nouveau possible de construire une image disque de bootstrap au moins pour la version PowerPC.
Le portage RISC-V a reçu une mise à jour vers gcc 13 (c’était déjà le cas pour les autres architectures) et a pu être utilisé pour compiler LLVM puis Mesa (l’intégration dans la ferme de compilation de Haikuports n’est pas encore en place, donc ces compilations doivent être faites par un développeur qui lance les commandes haikuports nécessaire et patiente longtemps pendant la compilation de ces gros projets).
Les versions 68000 et PowerPC ont été un peu dépoussiérées, mais il manque toujours un certain nombre de pilotes matériels de base pour pouvoir les utiliser sur de vraies machines et même dans une certaine mesure dans QEMU (ce dernier permettant d’émuler une machine utilisant de nombreux périphériques VirtIO, ce qui pourrait simplifier un peu les choses).
La bibliothèque libroot a reçu plusieurs mises à jour dans les parties qui nécessitent du code spécifique à chaque architecture, pour ajouter en particulier le RISC-V, et au passage plusieurs autres familles de processeurs.
Une partie de Haiku qui nécessite de grosses évolutions est la gestion des bus PCI. Le pilote existant supposait la présence d’un BIOS pour effectuer la découverte du bus, ou pouvait également utiliser des tables ACPI, mais d’une façon un peu limitée, qui repose tout de même sur le BIOS ou un quelconque firmware pour assigner des adresses valides à toutes les cartes PCI. Un problème identifié depuis longtemps puisqu’il s’agit du bug numéro 3 dans l’outil de suivi de bugs de Haiku. Ce bug fêtera ses 20 ans en mars prochain, espérons qu’il soit corrigé d’ici là. Les choses avancent, puisque le pilote PCI va maintenant s’attacher correctement aux noeuds ACPI correspondants dans le device tree, ce qui permet ensuite d’interroger ACPI pour découvrir les plages d’adresses mémoires disponibles pour l’allocation d’une adresse à chaque carte PCI connectée. Du côté des nouveaux ports de Haiku, cela va également permettre d’avoir plusieurs bus PCI “racine” indépendants. Et ces développements pourraient également Être utiles pour une prise en charge complète de Thunderbolt et USB 4.
Un autre pilote qui sera utile pour les versions ARM et RISC-V est le pilote SDHCI, qui permet de s’interfacer avec les lecteurs de cartes SD ainsi que les modules eMMC. Initialement destiné uniquement aux modules connectés sur un bus PCI, le pilote a été conçu pour être facilement extensible, et permet maintenant d’utiliser également les contrôleurs SDHCI exposés via ACPI. Cependant, le pilote a encore quelques problèmes de fiabilité, et il manque une implémentation des commandes nécessaiers pour les modules eMMC, qui partagent le même protocole de communication que les cartes SD, mais utilisent un jeu de commandes différent (il y a une petite guerre de standards, le format SD s’est imposé pour les cartes amovibles, mais MMC qui n’a pas de royalties a pu prendre le marché des modules soudés sur les cartes mères, où l’interopérabilité avec le matériel existant ne pose pas autant problèmes).
Le portage sur ARM64 avance petit à petit, il parvient à démarrer une partie de l’espace utilisateur et a reçu dernièrement des corrections sur le code permettant les changements de contexte entre différents threads. L’affichage du bureau complet pour la première fois sur une machine ARM64 ne devrait donc plus être très loin.
LOOM EXCHANGES
Le démarrage de Haiku est pris en charge par un bootloader spécifique nommé haiku_loader. Contrairement au noyau Linux, qui peut s’initialiser tout seul quasiment dès le démarrage du matériel, le noyau de Haiku a besoin que son bootloader prépare une grande partie de l’environnement (activation de la mémoire virtuelle, initialisation de l’affichage et mise en place du “splash screen”, par exemple). Le bootloader prend en charge toutes ces tâches et permet en plus de configurer des options de démarrage via un menu en mode texte, de démarrer via le réseau, d’utiliser un snapshot plus ancien du système si une mise à jour s’est mal passée.
Le bootloader a peu évolué cette année, le changement principal étant la suppression de logs de warning lors du chagement de fichiers ELF, pour les sections non traitées PT_EH_FRAME (généré par les versions modernes de gcc) ainsi que d’autres sections spécifiques aux processeurs RISC-V qui ne nécessitent pas de traitement spécifique dans ce cas.
DIME EXCHANGE
Beaucoup de travail a été fait sur l’amélioration des performances. C’est un sujet qui a été un peu laissé de côté au début du développement de Haiku. Le premier but était de faire fonctionner les choses, avant de les rendre plus rapides. Maintenant que les développements sont assez avancés, il est temps de commencer à étudier ce problème et à essayer de se rapprocher des perfomances d’autres systèmes.
GORILLA APP
Lorsqu’on veut lire ou écrire sur un disque, il faut envoyer une commande pour accéder à des secteurs consécutifs. Dans le cas normal, c’est le cache du système de fichiers qui se charge de regrouper les différents accès et de les ordonnancer de façon optimale.
Mais il y a un cas particulier pour les accès direct au disque. Par
exemple, si on ouvre le disque directement (via son device dans
/dev/disk/) ou encore lorsqu’un système de fichier veut écrire son
journal (qui ne passe pas par le cache). Les écritures dans le journal
sont faite avec des accès vectorisées (via readv ou
writev) qui contiennent chacun une liste d’endroits où lire
ou écrire des données. Ces accès étaient implémntés sous forme d’une
boucle appelant plusieurs fois read ou write.
Maintenant, la liste est directement transmise au pilote de disque qui
peut ainsi mieux traiter ces accès.
ADBANK APP
Haiku dispose d’un outil de profiling, mais celui-ci ne fonctionnait plus et retournait des données incohérentes. Plusieurs problèmes ont été corrigés pour faciliter les mesures de performances et vérifier que les optimisations rendent réellement les choses plus rapides.
MRLM 交易所
Le problème initial qui a conduit à ces améliorations était la lenteur du lancement de nouveaux processus. Un goulet d’étranglement qui a été identifié est le verrouillage du device_manager pour accéder au périphérique /dev/random pour initialiser le stack protector (qui a besoin d’écrire des valeurs aléatoires sur la pile). Toutes les ouvertures de fichiers dans /dev nécessitent d’acquérir un verrou qui empêche l’exécution en parallèle avec de nombreuses autres tâches liées aux périphériques matériels.
Le problème a été corrigé de deux façons: d’abord, le stack protector utilise une API permettant de générer des nombres aléatoires sans ouvrir de fichier dans /dev. D’autre part, une analyse a montré que la pile USB passait beaucoup de temps à exécuter du code en ayant verrouillé l’accès au device manager. Ce code a été modifié pour libérer le verrou plus souvent.
IS COINBASE WALLET A COLD WALLET
Un autre aspect assez lent du lancement de processus est le chargement des bibliothèques et la recherche des symboles dans ces bibliothèques. Pour identifier si une bibliothèque contient un symbole, la recherche se fait par un hash du nom de la fonction recherchée.
Historiquement, c’est la section DT_HASH qui est utilisée, mais les utils GNU implémentent également DT_GNU_HASH, qui utilise une meilleure fonction de hash et ajoute également un bloom filter qui permet de tester très rapidement, mais de façon imparfaite, la présence d’un symbole dans une bibliothèque.
Le chargeur de bibliothèques de Haiku sait maintenant utiliser les tables DT_GNU_HASH, mais ce n’est pas encore déployé car les gains de performances ne justifient pas l’augmentation de taille des bibliothèques (il faut stocker les tables dans l’ancien et dans le nouveau format). Il sera toutefois possible de l’ajouter au cas par cas sur les bibliothèques où le gain est important (par exemple s’il y a beaucoup de symboles).
YOUNG BOYS FAN TOKEN EXCHANGES
La fonction mmap permet de mapper un fichier directement
en mémoire. Les écritures en mémoire sont ensuite directement
enregistrées sur disque. Il n’est pas souahitable de charger tout le
fichier d’un coup au moment de l’appel à mmap, ce serait trop lent. Mais
il ne fait pas non plus attendre que le logiciel accède à cette mémoire
et remplir les données au goutte à goutte (ou plus précisément, une page
de 4Kio à la fois).
Un cas particulier est le traitement des bibliothèques partagées, qui sont chargées en mémoire de cette façon. Dans ce cas, le fichier est probablement déjà chargé quelque part en mémoire pour un autre processus, et il devrait être possible de réutiliser les mêmes données. Le code testant cette possibilité ne fonctionnait pas à tous les coups, ce qui fait que des fichiers qui auraient pu être mappés tout de suite, ne l’étaient pas.
Une autre amélioration est d’utiliser plusieurs allocateurs séparés pour chaque processeurs, pour réduire les blocages entre différents threads qui ont besoin de manipuler des pages de mémoire.
DRAGON COINS EXCHANGE
Les applications Haiku peuvent créer des zones de mémoires (appelées areas) qui disposent d’un identifiant unique et peuvent être partagées avec d’autres processus.
Lorsqu’une application s’arrête, il faut supprimer toutes les areas qui ont été créées. Cela était fait par une simple boucle supprimant ces zones une par une. Mais cela pose un problème: chaque suppression doit verrouiller la liste des areas puis la déverrouiller. Le code a été modifié pour verrouiller la liste une seule fois et retirer de la liste toutes les zones d’un seul coup, avant de faire les autres opérations de suppression qui n’ont pas besoin d’accéder à la liste.
Au total, toutes ces améliorations conduisent à une amélioration des performances de plus de 25% sur un test en condition réelles (compilation d’une partie des sources de Haiku).
YFIIGOLD EXCHANGES
Dans un autre domaine, une perte de temps conséquente est le calcul des checksums pour les paquets réseau reçus et envoyés. En effet, ce calcul était fait systématiquement par le logiciel, même si le matériel est capable de s’en charger. Il est maintenant possible pour les pilotes réseaux qu’ils sont capable de vérifier et de générer ces checksums par eux-même, et ainsi la pile réseau peut s’en dispenser. Cela permet aussi de se passer entièrement de checksums sur les interfaces localhost, qui ne devraient pas subir de corruption de paquets, et ne gagnent rien à cette vérification.
Cela a été également l’occasion de supprimer quelques copies des données des paquets réseau.
ZOSCHAIN EXCHANGE
La structure user_mutex joue un rôle similaire aux
futex de Linux. Elle est utilisée pour implémenter, par
exemple, pthread_mutex et pthread_rwlock.
L’implémentation avait plusieurs bugs (race conditions), et a été
remplacée par un nouveau système plus efficace.
Au total, toutes ces améliorations permettent des performances 25% meilleures que la version beta 4 de Haiku. Il reste cependant de quoi faire, puisque certains benchmarks (compilation d’une partie du code source de Haiku) restent près de 2 fois plus lent que l’opération équivalente sous Linux.
MY TOKEN EXCHANGES
Haiku est compilé avec gcc, ld et les binutils. Ils nécessitent tout trois un petit nombre de patchs maintenus dans un dépôt git dédié et reversés dans les versions upstream autant que possible. Une version de gcc 2.95.3 est également utilisée pour les parties du système assurant encore la rétro compatibilité avec BeOS, les versions plus récentes utilisent un mangling différent et ne sont pas inter opérables.
L’outil de compilation utilisé est Jam, développé à l’origine par Perforce et dont il existe plusieurs forks dont un maintenu par Boost et un autre par Freetype. Haiku utilise sa propre version de Jam avec de nombreuses évolutions.
Commençons la liste des changements dans cette section avec des mises à jour de dépendances : Haiku est maintenant compilé avec GCC 13.2 (la version 14 sera intégrée prochainement). La bibliothèque ICU utilisée pour implémenter toutes les fonctions d’internationalisation (qui se trouve donc avoir un rôle assez important dans la bibliothèque C standard) a été mise à jour en version 74.
Le travail pour supprimer tous les avertissements du compilateur se poursuit petit à petit, mais les problèmes restants sont de plus en plus difficiles à corriger, soit parce qu’il s’agit de code tiers (qu’il est plus facile de garder en l’état pour le synchroniser avec de nouvelles versions), soit parce que l’avertissement ne peut pas être corrigé proprement sans perte de performance, ou encore d’une façon qui contente à la fois gcc 13 et gcc 2 pour les parties du code compilées avec ces deux versions.
On peut toutefois mentionner que tous les trigraphes présents dans le code (par accident, par exemple il est facile d’écrire “??!” dans un commentaire) ont été supprimés. Ils ne sont plus disponibles dans C++ à partir de la version 17 et génèrent des erreurs de compilation.
D’autre part, l’option de compilation
-Wno-error=deprecated a pu être désactivée, car plus aucun
code ne déclenche cette erreur.
Puisqu’on parle d’options de compilation : l’optimisation “autovectorisation” pour la compilation du noyau a été désactivée pour l’instant. Cette option fait que le code utilise des instructions SSE, et faire cela dans le noyau problématique pour la plupart des machines virtuelles (QEMU, VMWare et Virtual Box). La plupart des autres noyaux n’utilisent pas ces instructions, ce qui fait que des bugs dans les hyperviseurs sont tout à fait possibles, par manque de tests. Mais le problème pourrait aussi venir de Haiku. L’investigation est pour l’instant remise à plus tard.
Un dernier changement dans le système de build consiste à permettre
l’utilisation de git worktree. Quelques commandes git sont
utilisées lors de la compilation pour calculer le numéro de version du
code en train d’être compilé, et ça ne fonctionnait pas correctement
dans ce cas de figure.
ZAYN LOGIN
La documentation de Haiku se découpe en 3 parties principales : un manuel de l’utilisateur, une documentation d’API, et une documentation interne pour les développeurs qui travaillent sur les composants du système.
Ces documents sont complétés par de nombreuses pages et articles sur le site internet, et deux livres pour apprendre à programmer en C++ avec Haiku, ou encore un document de référence pour la conception d’interfaces graphiques et un autre pour le style graphique des icônes.
KABY ARENA EXCHANGES
La documentation d’API de BeOS était assez complète et de bonne qualité. L’entreprise Access Co Ltd qui a hérité de la propriété intellectuelle de BeOS a autorisé le projet Haiku à la réutiliser et à la redistribuer. Malheureusement, cette autorisation est faite avec une licence Creative Commons n’autorisant pas les modifications. Cette documentation ne peut donc pas être mise à jour, ni pour corriger les erreurs, ni pour ajouter des informations sur toutes les nouvelles fonctions ajoutées par Haiku ou les différences entre les deux systèmes.
Il est donc nécessaire de réécrire une nouvelle documentation à partir de zéro. Ce travail est assez ingrat lorsqu’il s’agit de re-décrire ce qui est déjà très bien expliqué dans la documentation existante. La nouvelle documentation a donc tendance à se concentrer sur les nouvelles fonctions, et il faut souvent jongler entre les deux documentations, le contenu des fichiers .h, et des exemples de code d’applications existantes pour découvrir toutes les possibilités offertes.
Il ne semble pas utile de lister chaque fonction ou méthode qui a été documentée. On peut mentionner une page d’explications sur la bibliothèque C standard, comprenant des liens vers les spécifications POSIX qui documentent déjà la plupart des choses, et quelques détails sur les différences avec d’autres systèmes.
Une autre nouvelle page documente les primitives de synchronisation qui sont disponibles pour le code s’exécutant dans le noyau.
LEAGUE OF PETS EXCHANGE
La documentation interne était à l’origine simplement une accumulation de fichiers dans divers format dans un dossier “docs” du dépôt Git de Haiku. Depuis 2021, ces fichiers ont été rassemblés et organisés à l’aide de Sphinx, qui permet de mettre à disposition une version navigable en HTML et de donner une meilleure visibilité à ces documents.
D’autres pages sont petit à petit migrées depuis le site web principal de Haiku, qui n’est pas un très bon support pour de la documentation, et bénéficiera un jour d’une refonte pour être plus tourné vers les utilisateurs que vers les développeurs.
Quelques nouvelles pages ajoutées cette année:
- Une documentation sur l’utilisation de divers outils de complétion de code automatique avec le code source de Haiku
- Une page présentant l’organisation du code source et les principaux dossiers et sous-dossiers
- La documentation de l’outil
rcutilisé pour compiler les “resources” attachées aux exécutables a été intégrée - Le système de fichier FAT a reçu également une page de documentation à l’occasion de sa réécriture
SPACELENS EXCHANGE
L’association Haiku inc qui gère le compte en banque de Haiku publie chaque année un rapport financier.
Le financement provient principalement de dons des utilisateurs et supporters de Haiku. Le projet reçoit également une compensation financière de Google pour le temps passé à encadrer les participants du Google Summer of Code (voir le paragraphe suivant). La contribution de Google cette année est de 3300$.
Les plateformes de don les plus utilisées sont Paypal et Github sponsor. Ce dernier est recommandé car, pour les dons reçus via Github, c’est Microsoft qui paie les frais bancaires de la transaction. 100% de l’argent donné arrive donc sur le compte de Haiku. Tous les autres opérateurs ont un coût, soit fixe lors des retraits, soit un pourcentage de chaque don, soit un mélange des deux.
En 2023, l’association a reçu 25 422$ de dons et a dépensé 24 750$. Elle dispose d'une réserve confortable de 100 000$ (accumulés avant 2021, alors qu’il n’y avait pas de développeur salarié) ainsi que d’environ 150 000$ en cryptomonnaies.
Les dons en cryptomonnaies sont pour l’instant bloqués sur un compte Coinbase suite à des problèmes administratifs (le compte n’est pas correctement déclaré comme appartenant à une association, il faudrait donc payer un impôt sur le revenu lors de la conversion en vraie monnaie). Il semble difficile de contacter Coinbase pour régler ce problème.
Du côté des dépenses, le poste le plus important est le paiement de 21000$ à Waddlesplash, développeur employé par Haiku inc pour faire avancer le projet Haiku. Il travaille à temps partiel et avec un salaire très bas par rapport au marché, comme cela a été fait pour les précédents contrats entre Haiku inc et d’autres développeurs. Les finances de l’association ne permettent pas encore d’assurer un emploi à plein temps avec un salaire correct sur le long terme (c’est faisable sur le court ou moyen terme à condition de puiser dans les réserves de trésorerie).
Le reste des dépenses concerne principalement le paiement de l’infrastructure (serveurs pour le site internet, l’intégration continue, hébergement cloud pour les dépôts de paquets) pour environ 3000$.
Il faut enfin compter environ 500$ de frais Paypal, puis quelques dépenses administratives (déclaration de changement d’adresse de l’association, déclaration d’embauche) pour des montants négligeables (moins de 10$ au total).
En 2024, l’objectif fixé en janvier était de récolter 20 000$ de dons supplémentaires. Cet objectif a été atteint dès le mois de Juillet, et a donc été révisé pour tenter d’atteindre les 30 000$. Cela permettra de rémunérer Waddlesplash pour un plus grand nombre d’heures cette année, ou bien d’envisager l’embauche d’une deuxième personne si unë candidatë se présente parmi les personnes contribuant au projet (l’embauche d’une personne extérieure ne se fera pas tant que l’association ne peut pas se permettre de proposer une rémunération raisonnable).
COINS AND SKINS LOGIN
Haiku participe au Google Summer of Code depuis 2007. Il s’agit d’un programme ou des étudiants (et d’autres participants pas forcéments étudiants, ces dernières années) sont payés par Google pendant 2 mois pour découvrir la contribution à des projets de logiciels libres.
Ce programme a été monté par le “Open source program office” de Google. Leur intérêt est de défendre leur image d’entreprise sympathique (bien mise à mal ces dernières années, c’est devenu un géant de la publicité en ligne et de l’aspiration des données personnelles), et de contribuer à la richesse d’un écosystème de logiciels libres dont ils bénéficient beaucoup. Cela permet aussi d’encourager des personnes à s’essayer au développement logiciel, facilitant indirectement le recrutement chez Google en augmentant le nombre de candidats. Ces justifications peuvent sembler hypothétiques ou très indirectes, mais elles ont convaincu Google d’attribuer un budget de quelque millions de dollars à ce programme.
Une équipe de Google choisit les projets de logiciel libres participants parmi de nombreuses candidatures. Chaque projet participant propose une liste d’“idées” (un peu sous la forme d’un sujet de stage) et a ensuite la responsabilité de choisir parmi les candidats qui ont répondu à cette offre (en respectant les critères de non discrimination imposées par Google ainsi que les embargos imposés par les USA), et d’assurer l’encadrement des personnes sélectionnées. Google rémunère les participants, et dédommage les projets participants pour le temps investi.
Cette année les dévelopeurs de Haiku encadrent 5 participants :
LFEC LOGIN
Le système de fichier BFS utilisé par Haiku permet l’exécution de requêtes (comme une base de données) exploitant les attributs étendus des fichiers, qui peuvent être indexés.
Ce système permet de faire beaucoup de choses, et la fenêtre de recherche du navigateur de fichier essaie d’en tirer parti. Cependant, l’interface résultante est trop complexe, et peu de personnes prennent le temps de concevoir des requêtes améliorant leur façon de travailler, se cantonnant aux quelques exemples fournis.
L’objectif de ce projet est de refondre l’interface de cette fenêtre pour obtenir quelque chose de plus intuitif, et également d’afficher en temps réel les résultats de la requête dès qu’elle est modifiée, pour encourager les utilisateurs à expérimenter avec des requêtes plus complexes.
CMS 交易所
Haiku n’est pas encore parfait, et certaines tâches nécessitent encore l’utilisation d’autres systèmes d’exploitation. Une partie des utilisateurs ont donc une configuration en double boot, ou bien lancent Haiku dans une machine virtuelle.
L’objectif de ce projet est de permettre d’utiliser Haiku comme système principal, et de lancer les autres systèmes dans des machines virtuelles. Cela sera réalisé à l’aide d’un portage de NVMM, qui a été développé à l’origine par NetBSD et Dragonfly BSD. Cette bibliothèque a l’avantage d’être bien documentée et conçue pour faciliter son adaptation vers d’autres systèmes.
NVMM sera complétée par l’utilisation de QEMU qui pourra fournir un “front-end” à cette mécanique.
BEST FREE CRYPTO TRADING BOTS
Pour les personnes utilisant Haiku dans une machine virtuelle, il est intéressant d’utiliser autant que possible la famille de périphériques VirtIO.
Il s’agit de périphériques virtuels conçus sans s’inspirer de matériel existant, et plutôt pour avoir l’interface la plus simple possible entre la machine virtualisée et son hôte.
Haiku dispose déjà d’un jeu de pilote Virtio relativement complet (réseau, stockage de masse, affichage graphique). Le but de ce projet est de compléter cet ensemble avec un pilote pour les cartes son VirtIO.
COMMA 交易所
Haiku dispose de son propre débugger (appelé Debugger, de façon assez peu originale). Ce dernier présente une interface graphique confortable, mais une interface en ligne de commande beaucoup plus limitée. Il souffre également de quelques problèmes de performances et d’un manque de prise en charge des fichiers exécutables et bibliothèques compilés avec autre chose que GCC. Il est également incapable de faire du debug à distance ou de s’intégrer dans une interface graphique existante (par exemple au sein d’un IDE).
L’objectif de ce projet est de ressusciter la version de GDB ciblant Haiku. Cette version très ancienne était utilisée avant l’apparition du Debugger natif. Le projet est en bonne voie, le code d’interfaçage a été entièrement réécrit pour s’adapter aux versions modernes de GDB, et plusieurs évolutions et corrections ont été intégrées dans le système de debugging de Haiku (par exemple, pour mettre en pause tous les threads nouvellement créés afin que le debugger puisse les intercepter).
HAVEN PROTOCOL APP
Le navigateur WebPositive utilise le moteur de rendu webKit. Actuellement, il s’interface avec ce moteur via l’API WebKitLegacy. Cette API exécute tout le moteur de rendu web dans un seul processus, et ne fournit pas les garanties d’isolation nécessaires pour les navigateurs web modernes (que ce soit en terme de sécurité, ou en terme de fiabilité).
L’objectif de ce projet est de reprendre les travaux déjà entammés en 2019 pour migrer WebPositive vers la nouvelle API “WebKit2”, et bénéficier d’une séparation entre l’interface graphique, la communication réseau, et le rendu HTML/CSS/Javascript dans des applications séparées. Ainsi, un crash d’un de ces composants peut être récupéré de façon transparente sans faire disparaître toute l’application (et les données non enregistrées de l’utilisateur avec).
Le projet est également en bonne voie, un navigateur de test permet déjà d’afficher quelques pages ce qui montre que les bases sont en place. Il reste à régler de nombreux problèmes de rendu de texte, ainsi qu’à implémenter la gestion des entrées (clavier et souris) pour avoir un navigateur web utilisable. Il faudra ensuite migrer WebPositive vers ces nouvelles APIs.




